我们现在将重点放在将可微分物理(DP)设置与NN集成的方面。在使用DP方法进行学习应用时,关于DP和NN构建块的组合有很大的灵活性。由于一些差别非常微妙,下一节将更详细地讨论这些差别。我们将特别关注重复PDE和NN评估多次的求解器,例如,计算物理系统随时间变化的多个状态。
回顾一下,这是关于将NN和DP运算符相结合图示。在图中,这些运算符看起来像是一个损失项:它们通常没有权重,只提供一个梯度,影响NN权重的优化:
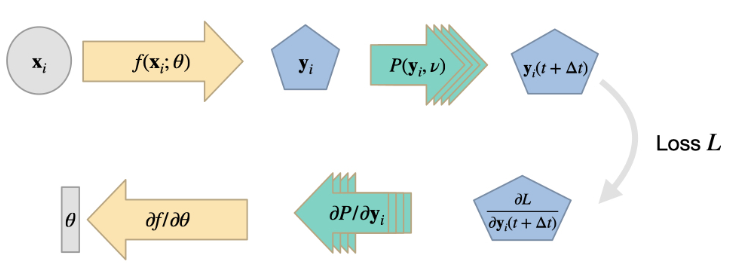
这个设置可以被视为网络接收关于其输出如何影响PDE求解器结果的信息。即梯度将提供如何生成最小化损失的神经网络输出的信息。类似于之前描述的"物理损失"(来自{doc}physicalloss),这可能意味着维持守恒定律。
这种设置可以看作是网络接收了关于其输出如何影响 PDE 求解器结果的信息。也就是说梯度将提供如何产生 NN 输出以最小化损失的信息。与之前描述的物理损失)类似,这可能意味着要坚持守恒定律。
11.1 更改顺序
但是,对于 DP 来说,我们没有理由局限于这种设置。例如,我们可以设想将 NN 和 DP 交换,从而得到以下结构:
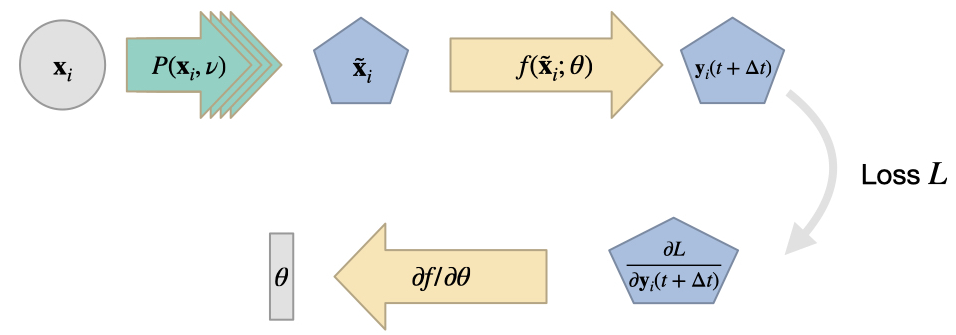
在这种情况下,PDE求解器本质上代表了一个即时生成数据的工具。这并不一定总是有用的:可以通过对相同输入进行预计算来替代这种设置,因为PDE求解器不受神经网络的影响。因此没有反向传播,可以被一个简单的"加载"函数替代。另一方面,在训练时使用随机采样的输入参数评估PDE求解器可以很好地对输入数据分布进行采样。如果我们对输入的变化范围有现实的了解,这可以改善神经网络的训练。如果正确实现,求解器还可以减轻存储和加载大量数据的需求,而是在训练时更快地生成这些数据,例如直接在GPU上生成。
然而,这个版本没有利用可微分求解器的梯度信息,这就是为什么下面的变体更加有趣的原因。
11.2 循环评估
一般来说,只要维度相容,没有任何NN层和DP操作符的组合是“禁止”的。其中一个特别有意义的组合是将模拟器的时间步进过程的迭代“展开”,并让系统的状态受到NN的影响。
在这种情况下,我们在正向传递中计算一系列(可能非常长)的PDE求解器步骤。在这些求解器步骤之间,NN修改系统的状态,然后用于计算下一个PDE求解器步骤。在反向传播过程中,我们通过所有这些步骤向后移动,以评估对损失函数的贡献(可以在执行链中的一个或多个位置进行评估),并通过DP和NN操作符反向传播梯度信息。这种求解器迭代的展开实际上向NN提供了关于其“行动”如何影响物理系统状态和损失的反馈。以下是这种组合形式的可视化概述:
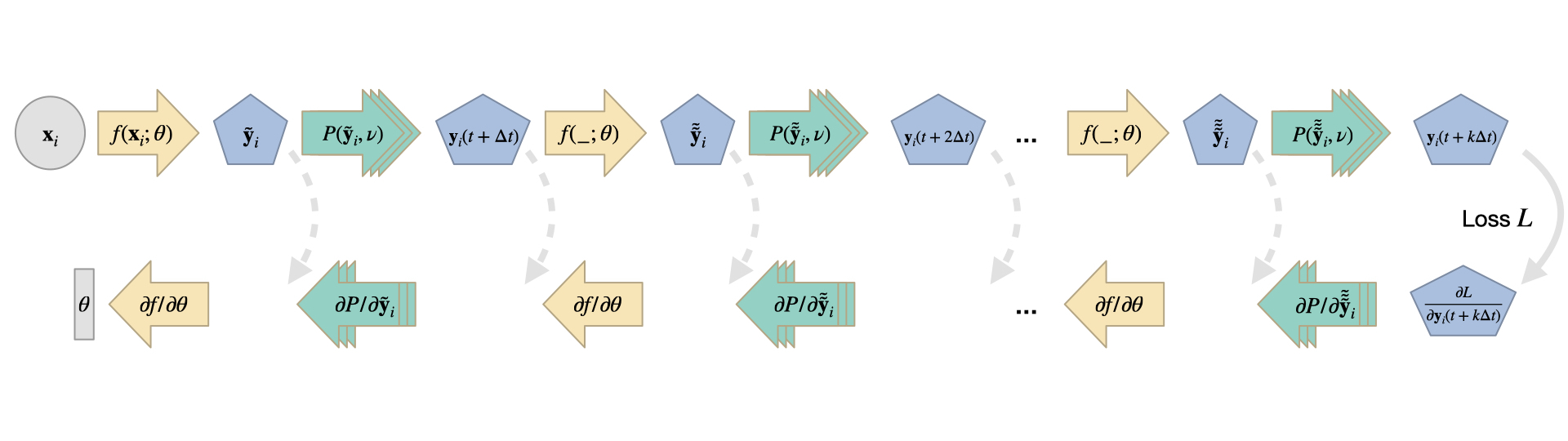
由于这个过程的迭代性质,错误一开始很小,然后在迭代过程中呈指数增长。因此,在单次评估中很难检测到这些错误,例如,在一个简单的监督训练设置中。相反,至关重要的是在训练时向神经网络提供有关错误如何随迭代过程而演变的反馈。此外,对于这种迭代的情况,无法进行状态的预计算,因为迭代取决于神经网络的状态。自然地,在训练之前,神经网络的状态是未知的,并且在训练过程中会发生变化。因此,在这些循环设置中,基于动态规划的训练对于向神经网络提供关于其当前状态如何影响求解器迭代以及相应地如何调整权重以更好地实现学习目标的梯度至关重要。
具有许多时间步的DP设置可能很难训练:梯度需要通过PDE求解器评估和神经网络评估的完整链路进行反向传播。通常,每个评估都代表一个非线性和复杂的函数。因此,对于更多步,梯度消失和梯度爆炸问题可能会导致训练困难。关于缓解这个问题的一些实际考虑将在 Reducing Numerical Errors with Deep Learning 中介绍。

11.3 NN 和求解器的组成
迄今为止,我们忽略了一个问题,即如何将神经网络的输出合并到迭代求解过程中。在上述图像中,神经网络似乎产生了物理系统的完整状态,并被用作的输入。这意味着对于步骤处的状态,神经网络产生了一个中间状态,求解器利用该状态生成下一步的新状态:。
虽然这种方法是可行的,但并不一定在所有情况下都是最佳选择。特别是如果神经网络只应该对当前状态进行修正,我们可以重用当前状态的部分。这样可以避免将神经网络的资源分配给已经正确的部分,即的某些部分。类似于U-Net的跳跃连接和ResNet的残差,这种情况下最好使用一个运算符来合并和,即。
在最简单的情况下,我们可以定义为加法,此时表示对的加性修正。简言之,我们通过评估来计算下一个状态。在这种情况下,网络只需要更新尚未满足学习目标的的部分。
一般来说,我们可以使用任何可微的运算符,它可以是乘法或积分方案。与损失函数类似,这个选择取决于具体问题,但加法通常是一个很好的起点。
11.4 方程形式
接下来,我们将正式描述前面段落中的内容。具体来说,我们将回答一个问题:对于雅可比矩阵,的更新步骤是什么样子的?给定一个带有索引的小批次和一个损失函数,我们将使用表示迭代中展开的总步数。为了缩短符号表示,表示在时间步时,批次的的状态。
利用这个符号表示,我们可以将网络权重的梯度写成:
乍一看,这个表达式似乎不太直观,但其结构相当简单:第一个求和式对于 累加了一个小批量中的所有条目。然后我们有一个对 (括号)的外部求和,涵盖了从 到 的所有时间步骤。对于每个 ,我们将沿着从最终状态 到每个 的链路追踪,通过沿途乘以所有雅可比矩阵(用索引 表示,括在括号中)来实现。沿途的每一步都由每个时间步长相对于 的雅可比矩阵组成,而这又取决于来自 NN 的修正(未写出)。
在神经网络的每个最后一步 ,我们“分支出”,确定在第 个时间步长时网络输出 和其权重 的变化。所有这些对于不同的 的贡献都被加起来,形成一个最终更新 ,用于我们训练过程中的优化器。
需要记住的是,对于大的 , 和 的递归应用的雅可比矩阵强烈影响后续时间步骤的贡献,因此稳定训练以防止梯度爆炸尤为关键。这是一个我们稍后将多次重访的主题。
在实现方面,所有深度学习框架都会重复使用重叠部分,这些部分针对不同的 重复。这在反向传播评估中自动处理,在实践中,求和将从大到小的 进行评估,以便我们在向小的 移动时“忘记”后续步骤。因此,反向传播步骤确实增加了计算成本,但通常与前向传递的计算成本相当,前提是我们有适当的运算符来计算 的导数。
11.5 通过求解器步骤进行反向传播
既然我们已经设置好了所有这些机器,一个很好的问题是:“使用可微分的物理模拟器进行训练真的能够改善情况吗?我们是否可以简单地展开一个监督式的设置,类似于标准的递归训练,而不使用可微分的求解器?”或者换一种说法,我们通过求解器的多步反向传播到底能获得多少好处?
简而言之,相当多!下面的段落展示了来自List等人的湍流混合层的评估案例,以说明这种差异。在进入细节之前,值得注意的是,这种比较使用了一个可微分的二阶半隐式流动求解器和一组定制的湍流损失项。因此,这不是一个玩具问题,而是展示了可微分性对于复杂的真实案例的影响。
这个案例的好处是,我们可以根据湍流案例的已建立的统计测量来评估它,并以这种方式量化差异。流动的能谱通常是一个起点,但我们将跳过它,并参考原始论文,而是更加关注两个更具信息量的指标。下面的图表显示了雷诺应力和湍流动能(TKE),都是以流动中的横截面的已解决量表示。橙色点表示参考解。

尤其是在彩色箭头所指示的区域,"展开监督"训练的红色曲线与参考解决方案的偏离更为明显。这两个测量值是在使用流体求解器和经过训练的神经网络进行1024个时间步骤的模拟后进行的。因此,这两个解决方案都相当稳定,并且比求解器的未修改输出要好得多,这在图表中以蓝色显示。
当定性比较涡度场的可视化时,差异在视觉上也非常明显:
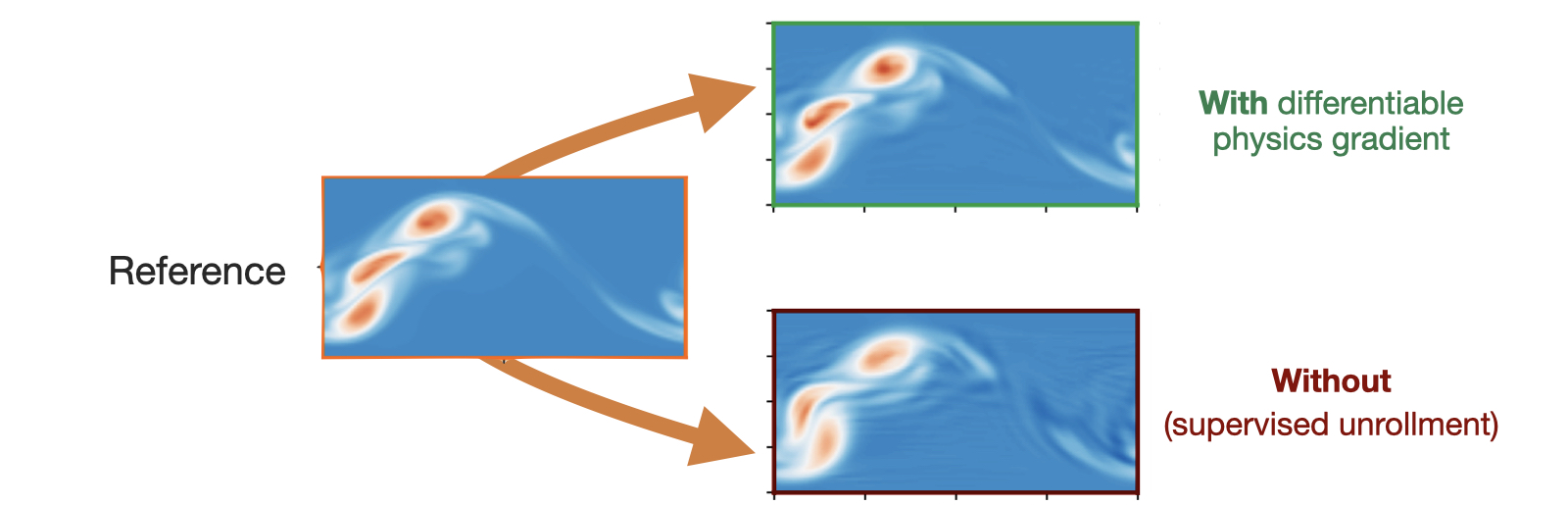
两个版本,有和无求解器梯度的版本,在这个比较中都极大地受益于展开,展开了10步。然而,没有动态规划的监督变体无法在训练时利用关于神经网络效果的长期信息,因此其能力受到限制。经过可微分求解器训练的版本在整个10步展开过程中都获得了反馈,并且通过这种方式可以推断出改进精度的校正,从而提高了由神经网络驱动的求解器的准确性。
展望未来,本案例还凸显了将 NN 纳入求解器的实际优势:我们可以测量常规模拟需要多长时间才能达到一定的湍流统计精度。在本例中,使用 NN {cite}"list2022piso "求解器所需时间是使用 NN"求解器所需时间的 14 倍以上。
虽然这只是第一个数据点,但我们很高兴地看到,一旦网络经过训练,或多或少就能在性能方面实现实际改进。
11.6 替代方法: 噪声
其他作品已经提出在训练时通过噪声扰动输入和迭代,这与像dropout这样的正则化器有些相似 {cite}sanchez2020learning。这可以帮助防止过度拟合训练状态,并且以这种方式可以帮助稳定训练迭代求解器。
然而,噪声的性质非常不同。它通常是无方向的,因此不如通过实际模拟演化进行训练准确。因此,噪声可以作为一个对于倾向于过度拟合的训练设置的良好起点。然而,如果可能的话,最好通过DP方法将实际求解器纳入训练循环中,以便网络可以获得关于系统时间演化的反馈。
11.7 复杂示例
下面的章节将给出更复杂情况的代码示例,以展示通过可微分物理训练可以实现什么。
首先,我们将按照Um等人的研究{cite}"um2020sol",展示一个利用深度学习来表示数值模拟误差的场景。这是一项非常基本的任务,需要学习到的模型与数值求解器密切互动。因此,在这种情况下,将数值求解器引入深度学习环路至关重要。
接下来,我们将展示如何让 NN 解决棘手的逆问题,即 Navier-Stokes 模拟的长期控制问题。这项任务需要长期规划,因此需要两个网络,一个预测演化,另一个采取行动以达到预期目标。(稍后,在 doc}reinflearn-code 中,我们将把这种方法与另一种使用强化学习的 DL 变体进行比较)。
这两种情况都比前面的例子需要更多的资源,所以你可以预期这些笔记本运行的时间会更长(在处理这些例子时,使用检查点是个好主意)。