使用基于查询的选择
对于需要选择对象的属性,可以应用动态查询,即:使用过滤条件定义选择中要包括的对象。添加、移除或修改对象时,Simcenter STAR-CCM+ 会自动计算所选内容。
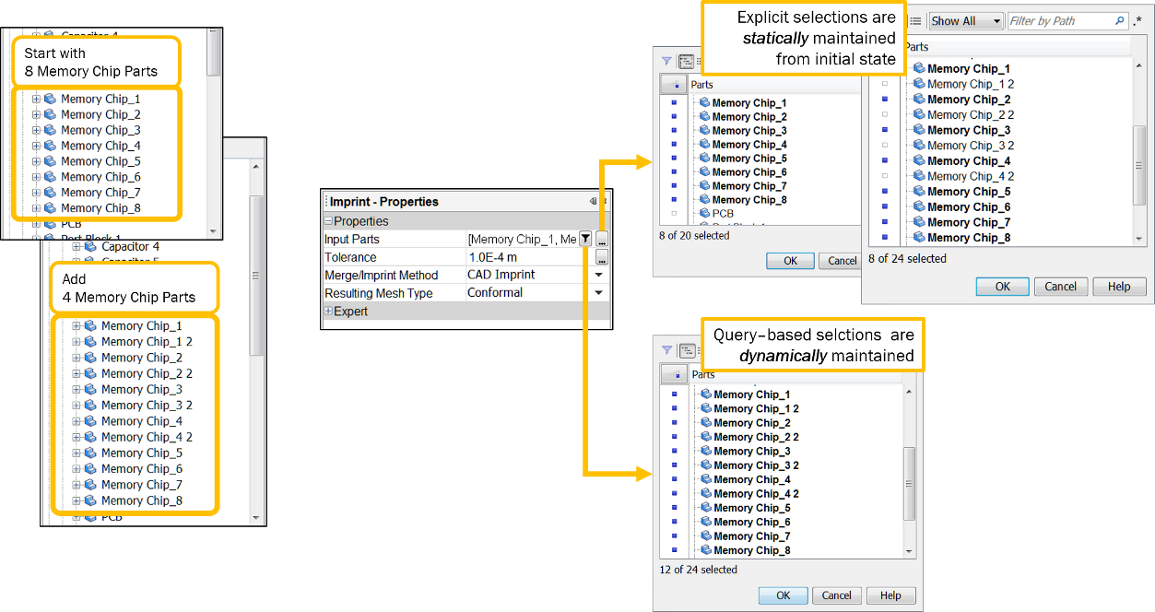
只要看到查询编辑器按钮 ( ),即表示动态查询可用。
),即表示动态查询可用。
高效动态查询的注意事项
动态查询会影响模拟的性能,因此应谨慎使用。通常,此性能开销会发生在编辑期间(即,将对象添加到查询选择中或从查询选择中移除对象时),而非发生在运行时间较长的操作中(如网格化和求解)。
因素
影响查询性能的常见因素包括:
- 谓词的出现顺序
- 要计算的对象数
- 要计算的谓词数
- 使用的谓词组合
- 要查询的对象类型
策略
- 多级嵌套查询谓词会影响计算时间。尝试编写简短、高效的查询。
- 可排除大多数对象的查询谓词通常应放在查询谓词列表开头。这将限制为后续谓词计算的对象数。有关更多详细信息,请参见关于顺序如何影响查询效率的示例。
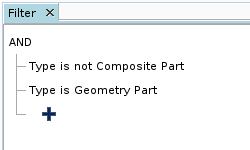
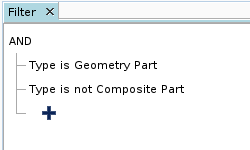
效率较低的查询 效率较高的查询 - 如果条件允许,尽量使用 AND 而不是 OR 来联接谓词。
- 某些谓词类型比其他谓词类型效率更高。类型、名称和标签谓词通常效率更高。关系、元数据和继承零部件谓词效率最低。
如果能以最短的查询获得所需的查询结果,即便是效率最低的谓词也可以使用。
激活动态查询
要激活动态查询:
- 单击属性(通常是零部件属性)右半部分的查询编辑器按钮 ()。

- 定义用于选择对象的查询。定义此查询的方法与过滤器相同。有关详细信息,请参见使用过滤器。
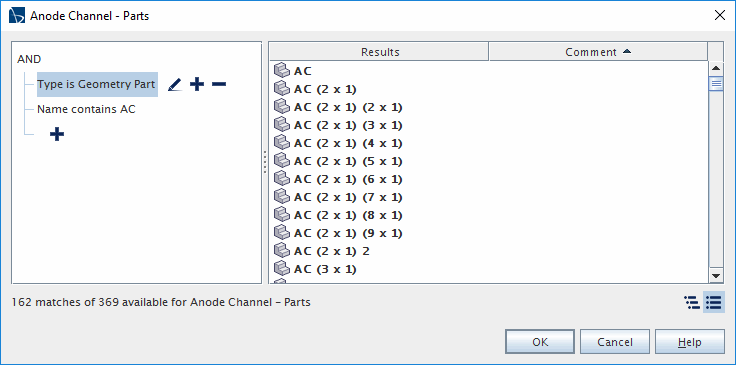
在对话框的左下角,文本表示匹配数。
| 注 |
|
确定零部件分配优先级
当使用动态查询选择跨多个类似对象分配零部件时,需要确定额外优先级。使用 Simcenter STAR-CCM+,可以通过动态查询选择来定义对象接收零部件的优先级。列表中靠前的对象比靠后的对象优先接收零部件。
确定分配优先级的对象类型有区域、边界、子分组(在区域和边界上)和边界交界面。对于这些类型的对象,包含它们的管理器节点显示零部件选择优先级属性,该属性包含优先级列表。对象出现在优先级列表中的顺序决定了 Simcenter STAR-CCM+ 向需要零部件的对象属性分配零部件的顺序 — 当动态查询替代静态零部件列表时。
例如,假设区域节点中有两个区域 EngineRegion 和 CompressorRegion。需要向 EngineRegion 自动分配名称中含有 Engine 的所有零部件,向 CompressorRegion 自动分配名称中含有 Compressor 的所有零部件。对于 EngineRegion 的零部件属性,定义动态查询 Name contains Engine;而对于 CompressorRegion 的零部件属性,定义动态查询 Name contains Compressor。
这些查询成功分配零部件,如 Compressor-Duct-1、Compressor-Chamber-1、Engine-Port-1、Engine-Port-2 等。但是,如果添加零部件 Engine-Compressor-Inlet1,则无法提前说明是 EngineRegion 还是 CompressorRegion 接收零部件。
要确保将此类零部件分配到 CompressorRegion,需要使用以下方法:
- 选择区域管理器节点。
- 在零部件选择优先级属性中,单击
 (自定义编辑器)。
(自定义编辑器)。 - 在区域 - 零部件选择优先级对话框中,指定优先级。在此示例中,确保 CompressorRegion 显示在列表的顶部。。
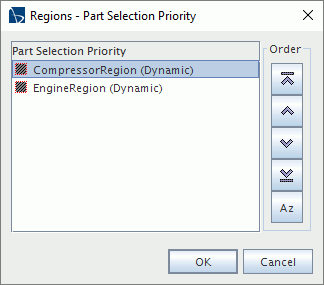
使用任何按钮(从顶部至底部),如下所示:
- 移至顶部:将区域移至列表顶部
- 上移:将区域上移一个位置
- 下移:将区域下移一个位置
- 移至底部:将区域移至列表底部
- 按字母顺序排列整个列表:按字母顺序为项重新排序
- 单击确定。
现在,当 Simcenter STAR-CCM+ 检测到 CompressorRegion 和 EngineRegion 的动态查询可接受零部件 Engine-Compressor-Inlet1 时,Simcenter STAR-CCM+ 为 CompressorRegion 赋予高于 EngineRegion 的优先级。
使用这些对象时考虑以下事项:
- 无论零部件选择优先级对话框中指定的顺序如何,包含静态分配的零部件的区域(即采用标准方法将零部件手动分配到区域)的优先级都会高于包含动态分配的零部件的区域。这些区域出现在对话框中,以允许分配查询之前或之后设置优先级。但是,一旦静态分配零部件,则将其移除的唯一方法是手动取消选择它,或将它分配到另一个区域。
- 边界和边界交界面的工作方式与区域相同。但是,由于零部件接触仅分配到边界交界面,因此零部件选择优先级对话框中不列出非边界交界面。
关于顺序如何影响查询效率的示例
本示例将展示如何将查询所扫描的对象数从 54,800 个减少到 25,450 个,从而缩短计算所需的时间。假设模拟的内容如下:
- 查询可扫描 25,000 个对象,
- 其中 5,000 个是几何零部件。
- 100 个几何零部件是特殊的复合零部件。
- 在 25,000 个对象中,有 250 个对象的名称中含有
steel(钢)一词。 - 在这 250 个对象中,有 200 个是几何零部件,其中包括 5 个特殊的复合零部件。
目的是编写一个动态查询,返回属于非复合部件且名称中含有 steel(钢) 一词的所有几何部件。
具有以下三个谓词且由 AND 连接的查询过滤器可返回正确的结果:
类型不是复合零部件类型是几何零部件名称包含 steel
考虑执行查询过滤器计算所需的时间时,顺序非常重要。以上述列表中的顺序为例:
类型不是复合零部件— 该谓词会扫描 25,000 个对象并返回 24,900 个。类型是几何零部件— 该谓词会扫描剩下的 24,900 个对象并返回 4,900 个。名称包含 steel— 该谓词会扫描剩下的 4,900 个零部件并返回 195 个。
扫描的对象总数为 54,800 个。
了解模拟的构成有助于提高上述查询过滤器的效率。第一个谓词扫描了 25,000 个对象,但仅排除了其中的 100 个对象。第二个谓词在排除后剩下了 4,900 个对象,因此重新排序前两个谓词会让查询效率更高:
类型是几何零部件— 该谓词会扫描 25,000 个对象并返回 5,000 个。类型不是复合零部件— 该谓词会扫描 5,000 个对象并返回 4,900 个。名称包含 steel— 该谓词会扫描剩下的 4,900 个零部件并返回 195 个。
扫描的对象总数为 34,900 个。
了解名称中含有 steel(钢) 一词的对象不多这一情况后,还可以进一步改进查询过滤器:
名称包含 steel— 该谓词会扫描剩下的 25,000 个零部件并返回 250 个。类型是几何零部件— 该谓词会扫描 250 个对象并返回 200 个。类型不是复合零部件— 该谓词会扫描 200 个对象并返回 195 个。
扫描的对象总数为 25,450 个,比第一次扫描少了一半,比第二次扫描少了 9,000 个以上。