
UDF除了可以以解释的方式外,其还可以以编译的方式被Fluent加载。解释型UDF只能使用部分C语言功能,而编译型UDF则可以全面使用C语言的所有功能。
1
编译型UDF介绍
编译型UDF在编译构建过程中,其利用一个名为Makefile的脚本文件来调用C编译器构建一个目标代码库。该对象库与其编译过程中所使用的Fluent版本及计算机体系结构相关。因此,若改变了计算机操作系统或Fluent版本的话,UDF对象库必须重新构建。UDF的编译过程通常涉及到源代码的编译和加载两个步骤。
编译/构建过程需要一个或多个UDF的源文件(例如myudf.c),并将它们编译成对象文件(例如myudf.o或myudf.obj),之后将其构建成一个“共享库” (例如,libudf.dll)与目标文件。
如果使用GUI方式编译源文件,则当用户单击“Compiled UDF”对话框中的“Build”按钮时,将执行编译/构建过程。Fluent软件将自动为用户基于在该会话期间运行的ANSYS Fluent的体系结构和版本(例如,hpux11 / 2d)构建用户命名的共享库(例如libudf),并存储UDF对象文件。
如果使用TUI方式编译源文件,则首先必须设置共享库的目标文件夹,同时修改名为Makefile的脚本文件以指定源参数,然后执行Makefile文件实现源代码的编译与构建。使用TUI方式编译UDF具有允许从非ANSYS Fluent源派生的预编译对象文件链接到ANSYS Fluent(链接非ANSYS Fluent源文件预编译的对象文件)的诸多优点,这些功能用GUI编译无法实现。
构建共享库(使用TUI或GUI)后,将UDF库加载到ANSYS Fluent中,然后再使用它。您可以使用“Compiled UDFs”对话框中的“Load”按钮来执行此操作。加载完成后,共享库中包含的所有已编译的UDF将在ANSYS Fluent的图形对话框中变为可见和可选。请注意,编译的UDF显示在ANSYS Fluent对话框中,相关联的UDF库名称由两个冒号(::)分隔。例如,与名为libudf的共享库相关联的名为rrate的编译型UDF将出现在ANSYS Fluent对话框中,如rrate :: libudf。此名称可以区分解释型UDF和编译型UDF。
如果在加载UDF库时写入您的Case文件,则库将与Case文件一起保存,并在之后读取该Case文件时自动加载。这种“动态加载”过程可以节省用户每次运行模拟时重新加载编译库的时间。
2
C编译器
不管是使用GUI还是使用TUI方式编译UDF,都需要使用本机运行的操作系统以及C编译器。大多数的Linux操作系统上都已经集成了C编译器,但是如果是在Microsoft Windows系统上编译UDF,则在编译之前必须确保本机上已经安装了MicroSoft Visual Studio。 对于Linux机器,ANSYS Fluent支持任意符合ANSI标准的C编译器(如GCC)。
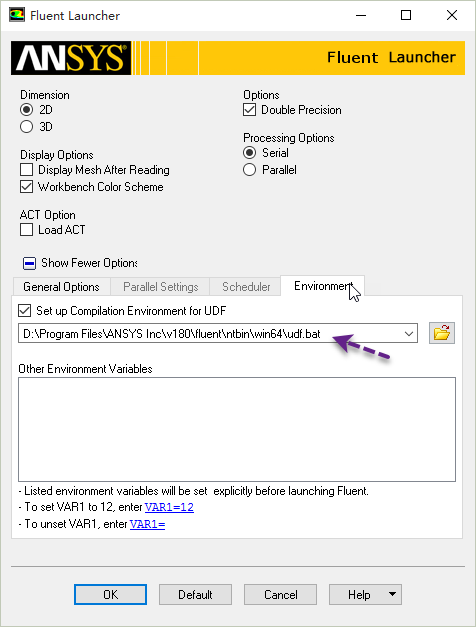
在进行UDF编译之前,需要设置编译环境,这通常可以通过修改UDF.bat文件来实现。如下图所示。
3
GUI方式编译UDF
利用GUI方式编译UDF源文件、构建共享库以及加载UDF库到Fluent中,可以采用以下步骤。
注意:在Windows系统下编译UDF,必须预先安装Visual Studio。在安装Visual Studio时,确保选择安装c++语言,这样才会安装C编译器。
-
确保要编译的UDF源文件与cas和dat文件在同一工作路径下。
-
读取(或创建)case文件
-
打开
Compiled UDFs对话框。可通过树形菜单Parameters & Customization → User Defined Functions→Compiled...启动该对话框。
-
在
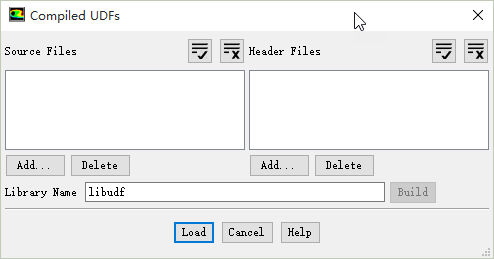
Compiled UDF对话框中点击按钮Add...添加源文件和头文件 -
在
Library Name后的文本框中输入共享库的名称,之后点击Build按钮构建共享库。其间会弹出如下图所示的提示对话框。
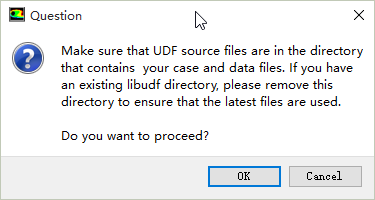
可以选择无视,点击OK按钮继续。
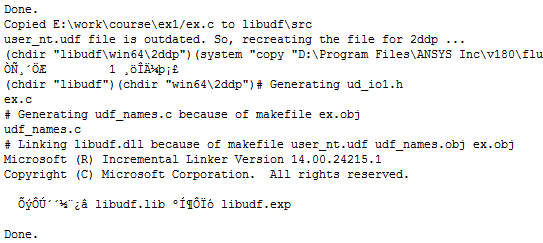
编译完成后会在TUI窗口出现如图所示的对话框。仔细检查提示信息,没有出现error则表示编译成功。图中出现有乱码,不知道是从Fluent哪个版本开始就出现这种情况。其实可以不用管。
-
点击
Load按钮加载UDF
如果没有错误的话,加载完housing会在TUI窗口中出现如下图所示的对话框,其中会显示UDF宏名称。如下图中所示的velocity和domainInit。

4
TUI方式编译UDF
除了可以利用图形界面编译UDF外,Fluent还提供了利用TUI命令的方式编译UDF。利用TUI方式进行编译,能够允许用户调用一些非Fluent源文件之外的库文件。
使用TUI进行编译,通常首先需要创建好文件目录结构,之后编辑Makefile文件,利用makefile文件编译源文件。
windows系统与Linux系统的编译方式有些不同,这里主要描述Windows下的构建过程,linux系统后面再说。
在windows系统中编译UDF,需要两个文件makefile_nt.udf与user_nt.udf。特别重要的是在user_nt.udf文件中指定源文件编译参数。构建文件目录结构采用以下步骤:
-
在当前工作目录下,创建新的文件夹存储UDF库。(例如创建文件夹libudf)
-
在libudf文件夹下创建新的文件夹,命名为
src -
将所有UDF源文件放入src文件夹中
-
在libudf文件夹下创建架构文件夹。如64bit windows操作系统,则创建win64文件夹(路径libudfwin64)。
-
在架构文件(libudfwin64)下创建Fluent版本文件夹。如单精度2d版本则创建文件夹2d。一些版本信息如下表所示。
| 版本信息 |
文件夹名字 |
|
单精度2d |
2d |
|
当精度3d |
3d |
|
双精度2d |
2ddp |
|
双精度3d |
3ddp |
|
单精度并行2d |
2d_node及2d_host |
|
单精度并行3d |
3d_node及3d_host |
|
双精度并行2d |
2ddp_node及2ddp_host |
|
双精度并行3d |
3ddp_node及3ddp_host |
注意:在编译并行UDF时,需要创建两个版本文件夹。
-
从Fluent安装路径中(如c:ANSYS Incv180fluentfluent18.0.0src)拷贝文件
user_nt.udf到所有的版本子文件夹中(如libudfwin643d) -
从Fluent安装路径中(如c:ANSYS Incv180fluentfluent18.0.0src)拷贝文件
makefile_nt.udf到所有的版本子文件夹中(如libudfwin643d),并改名为makefile
注意:若在Fluent外部编译UDF,则需要添加环境变量FLUENT_INC、FLUENT_ARCH到user_nt.udf文件中

Linux环境下的文件目录设置与此有些许差异。
当文件目录设置完毕并且所有文件已经放置到指定位置后,就可以利用TUI来编译及构建UDF共享库了。
在windows系统中,采用以下步骤:
-
修改
user_nt.udf文件。修改文件中的三个参数:CSOURCES、HSOURCES、VERSION以及PARALLEL_NODE
udf_nt.udf文件内容类似下图所示。
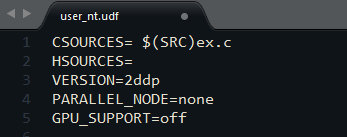
CSOURCES=:指定要编译的UDF源文件。在所有文件名前面加上前缀$(SRC)。(多个文件可以连着写,如$
HSOURCES=:指定要编译的UDF头文件。同样在所有文件名前面加上$(SRC)前缀。(多个文件可以连着写,如$
VERSION=:运行的求解器版本信息,与user_nt.udf文件所在文件夹保持一致。((2d, 3d, 2ddp, 3ddp, 2d_host, 2d_node, 3d_host, 3d_node, 2ddp_host, 2ddp_node, 3ddp_host, or 3ddp_node)。
PARALLEL_NODE=指定并行通讯库。指定为None表示采用串行,其他并行包括:ibmmpi(利用IBM MPI并行)、intel(利用intel MPI并行)以及msmpi(利用微软MPI)。在并行计算中需要同时设置host及node文件夹下的user_nt.udf文件。
-
利用Visual Studio命令行界面进入每一个版本文件夹(如libudfwin642d),输入
nmake执行编译操作。若编译存在问题,可以在修改源文件后通过执行nmake clean及nmake重新编译。


本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册