
UDF宏有两种方式可以被Fluent所接受:编译和解释。其中有一些宏既可以被解释也可以被编译,而一些宏则只能被解释。有一些场合只接受编译后的UDF(如动网格中的一些宏),而有些场合既可以接受编译的UDF,还能接受解释后的UDF。那么解释型的UDF与编译型的UDF到底存在何种差异?本文主要描述解释型UDF,而编译型UDF涉及到的问题更多,我们留到下次再说。
1
解释型UDF
解释型UDF不需要额外的编译器,利用Fluent软件自身即可解释源代码。在解释过程中,UDF源代码被C预处理器解释成中间的,独立于计算机体系之外的机器代码。之后在调用UDF的过程中,这些被解释器生成的机器代码将在内部仿真器或解释器上被执行。当然,这种以解释的方式运行无可避免的会损失计算性能。但是以解释方式运行的UDF有个好处:其可以不加修改的在不同体系的计算机上、不同的操作系统以及不同的Fluent版本中运行。
当UDF的计算性能很重要时,建议以编译的形式运行UDF。所有解释型UDF都可以以编译的方式被Fluent加载。
在UDF被解释后保存cas文件,之后再打开cas文件时,UDF能够直接被加载,而无需重新解释。
2
解释型UDF的局限性
解释型的最大优势是一次解释,到处可以执行,能够跨平台、跨架构、跨操作系统、跨版本。但是解释型UDF也存在其局限性。主要体现在:
-
无法使用
goto语句 -
只支持ANSI-C语法
-
不支持直接数据结构引用(direct data structure references)
-
不支持局部结构声明
-
不支持联合体
-
不支持指向函数的指针
-
不支持函数数组
在访问FLUENT求解器数据的方式上解释式UDF也有限制。解释式UDF不能直接访问存储在FLUENT结构中的数据。它们只能通过使用Fluent提供的宏间接地访问这些数据。另一方面,编译式UDF没有任何C编程语言或其它注意的求解器数据结构的限制。
3
在Fluent中解释UDF
在Fluent中解释UDF非常简单。通常可采用以下步骤:
-
确保UDF源文件与cas文件在同一目录下。
需要说明的是,在网络式多机并行Fluent中,用户必须共享包含udf源文件、cas文件以及data文件的文件夹。具体共享方法为: 鼠标右键选择要共享的工作文件夹,选择弹出菜单Sharing and Security,并选择Share this folder。
-
右键选择模型树节点Parameters&Customization→User Defined Functions,选择子菜单Interpreted..
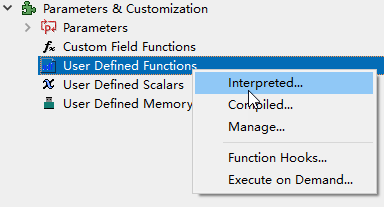
弹出如下图所示的对话框。
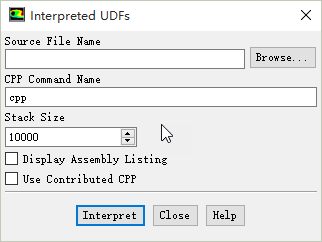
-
在对话框中选择按钮Browse…
在弹出的文件选择对话框中选择UDF源文件。对话框中的其他参数一般情况下可保持默认设置。
-
点击按钮Interpret解释源文件
源文件解释过程中,TUI窗口会有解释信息。若有错误的话,会出现错误信息。
-
加载解释后的UDF
当源代码被解释后,在相应的GUI窗口中就可以看到被解释的UDF了,此时可以选择使用。


本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册