
以下内容来自维基百科:
Scheme是一种函数式编程语言,是Lisp的两种主要方言之一(另一种为Common Lisp)。不同于Common Lisp,Scheme遵循极简主义哲学,以一个小型语言核心作为标准,加上各种强力语言工具(语法糖)来扩展语言本身。
MIT与其他院校曾采用Scheme教授计算机科学入门课程。著名的入门教材《计算机程序的构造和解释》(SICP)利用Scheme来解释程序设计。Scheme的广泛受众被视为一个主要优势,然而不同实现之间的差异成为了它的一个劣势。
Scheme最早由MIT的 Gerald J. Sussman 和 Guy L. Steele Jr.在1970年代发展出来,并由两人发表的“λ论文集”推广开来。 Scheme语言与λ演算关系十分密切。小写字母“λ”是Scheme语言的标志。
Scheme的哲学是:设计计算机语言不应该进行功能的堆砌,而应该尽可能减少弱点和限制,使剩下的功能显得必要。Scheme是第一个使用静态作用域的Lisp方言,也是第一个引入“干净宏”和第一类续延的编程语言。
更多关于Scheme语言的介绍,可查看维基百科相应词条。
关于Scheme的教材:
-
《计算机程序的构造和解释》(SICP)是最著名的使用Scheme语言的计算机科学教科书,由Scheme创始人之一萨斯曼与Harold Abelson编写。

-
《程序设计方法》对SICP中的一些被认为过于艰涩的概念进行了改进,由Felleison等人编写。

-
Simply Scheme是一本专为中学级别,无计算机科学基础的学生编写的入门书,由伯克利加州大学资深讲师布莱恩·哈维编写。

-
《The Scheme Programming Language》:目前为第四版,可用在网站https://scheme.com/tspl4/在线阅读。

Scheme语言是一种解释型计算机语言,目前比较常用的是DrRacket及chez Scheme,两个都是免费可用的。
-
chez Scheme:可在网站https://cisco.github.io/ChezScheme/找到详细描述及相应文档。
-
DrRacket:可在网站http://racket-lang.org/找到其具体描述及文档。
要编制程序,首先要编写源代码。Scheme的源代码可用采用任何文本编辑器进行编写。但为了提高效率,能够进行语法高亮的编辑器自然是优先选择。
常用的编辑器:
-
Visual Studio Code:微软搞出来的开源IDE,深受程序猿的喜爱。免费开源的代码编辑器。工作界面如下图所示。
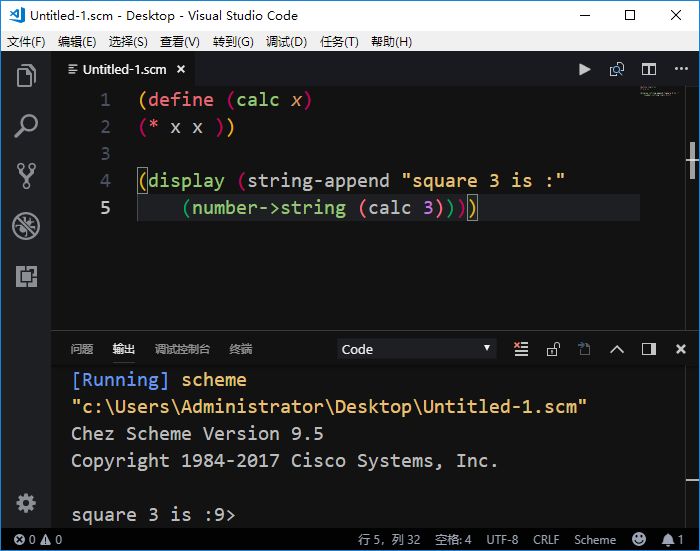
-
DrRacket:DrRacket提供的代码编辑工具。工作界面如下图所示。
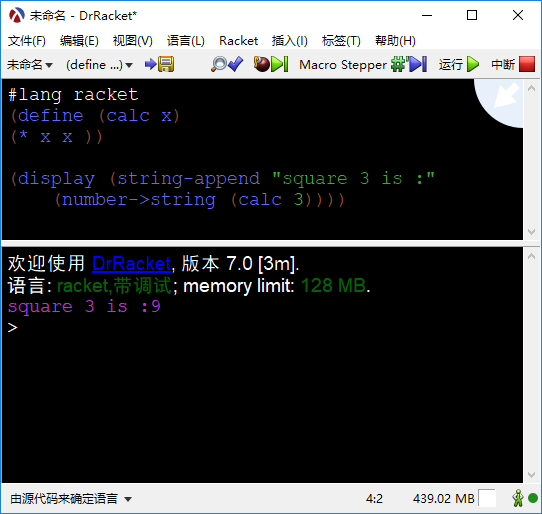
-
sublime text:一个文本编辑工具,诸如此类的工具很多,如notpad++,notepad2、ultraEdit等等。
-
Fluent TUI
事实上,也开源将Fluent的TUI窗口当做一个Scheme语言的编辑器。如在TUI窗口中定义函数计算变量的平方值,如下图所示。
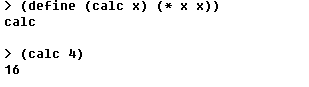
以下内容来自网址https://www.ibm.com/developerworks/cn/linux/l-schm/index1.html,部分作了修正。
Scheme语言中的注释是单行注释,以分号[;]开始一直到行尾结束,其中间的内容为注释,在程序运行时不做处理,如:
; this is a scheme comment line.
标准的Scheme语言定义中没有多行注释,不过在它的实现中几乎都有。在Scheme中就有多行注释,以符号组合"#!"开始,以相反的另一符号组合"!#"结束,其中内容为注释,如:
#!there are scheme comment area.``you can write mulity lines here . !#
注意的是,符号组合"#!"和"!#"一定分做两行来写。
Scheme语言可以象sh,perl,python等语言那样作为一种脚本语言来使用,用它来编写可执行脚本,在Linux中如果用Scheme语言写可执行脚本,它的第一行和第二行一般是类似下面的内容:
#! /usr/local/bin/Scheme -s``!#`
这样的话代码在运行时会自动调用Scheme来解释执行,标准的文件尾缀是".scm"。
块(form)是Scheme语言中的最小程序单元,一个Scheme语言程序是由一个或多个form构成。没有特殊说明的情况下 form 都由小括号括起来,形如:
(define x 123)
(+ 1 2)
(* 4 5 6)
(display "hello,world")
一个 form 也可以是一个表达式,一个变量定义,也可以是一个过程。
Scheme语言中允许form的嵌套,这使它可以轻松的实现复杂的表达式,同时也是一种非常有自己特色的表达式。 下图示意了嵌套的稍复杂一点的表达式的运算过程:
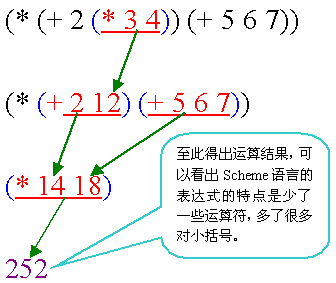
可以用define来定义一个变量,形式如下:
(define 变量名 值)
如: (define x 123) ,定义一个变量x,其值为123。
可以用set!来改变变量的值,格式如下:
(set! 变量名 值)
如: (set! x "hello") ,将变量x的值改为"hello" 。
Scheme语言是一种高级语言,和很多高级语言(如python,perl)一样,它的变量类型不是固定的,可以随时改变。
逻辑型(boolean)
最基本的数据类型,也是很多计算机语言中都支持的最简单的数据类型,只能取两个值:#t,相当于其它计算机语言中的 TRUE;#f,相当于其它计算机语言中的 FALSE。
Scheme语言中的boolean类型只有一种操作:not。其意为取相反的值,即:
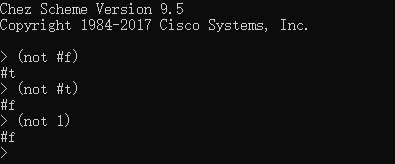
not的引用,与逻辑非运算操作类似
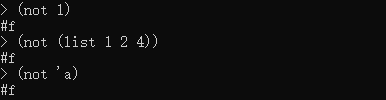
从上面的操作中可以看出来,只要not后面的参数不是逻辑型,其返回值均为#f。
数字型(number)
它又分为四种子类型:整型(integer),有理数型(rational),实型(real),复数型(complex);它们又被统一称为数字类型(number)。
如:
复数型(complex) 可以定义为 (define c 3+2i)实数型(real)可以定义为 (define f 22/7)有理数型(rational)可以定义为 (define p 3.1415)整数型(integer) 可以定义为 (define i 123)
Scheme语言中,数字类型的数据还可以按照进制分类,即二进制,八进制,十进制和十六进制,在外观形式上它们分别以符号组合 #b、 #o、 #d、 #x 来作为表示数字进制类型的前缀,其中表示十进制的#d可以省略不写,如:二进制的 #b1010 ,八进制的 #o567,十进制的123或 #d123,十六进制的 #x1afc 。
Scheme语言的这种严格按照数学定理来为数字类型进行分类的方法可以看出Scheme语言里面渗透着很深的数学思想,Scheme语言是由数学家们创造出来的,在这方面表现得也比较鲜明。
字符型(char)
Scheme语言中的字符型数据均以符号组合 "#" 开始,表示单个字符,可以是字母、数字或"[ ! $ % & * + - . / : %lt; = > ? @ ^ _ ~ ]"等等其它字符,如:#A 表示大写字母A,#�表示字符0,其中特殊字符有:#space 表示空格符和 n 表示换行符。

符号型(symbol)
符号类型是Scheme语言中有多种用途的符号名称,它可以是单词,用括号括起来的多个单词,也可以是无意义的字母组合或符号组合,它在某种意义上可以理解为C中的枚举类型。看下面的操作:

此处也说明单引号' 与quote是等价的,并且更简单一些。符号类型与字符串不同的是符号类型不能象字符串那样可以取得长度或改变其中某一成员字符的值,但二者之间可以互相转换。
可以说复合数据类型是由基本的简单数据类型通过某种方式加以组合形成的数据类型,特点是可以容纳多种或多个单一的简单数据类型的数据,多数是基于某一种数学模型创建的。
字符串(string) 由多个字符组成的数据类型,可以直接写成由双引号括起的内容,如:"hello" 。下面是Scheme中的字符串定义和相关操作:

字符串还可以用下面的形式定义:

字符串中出现引号时用反斜线加引号代替,如:"abc"def" 。
点对(pair)
我把它译成"点对",它是一种非常有趣的类型,也是一些其它类型的基础类型,它是由一个点和被它分隔开的两个所值组成的。形如: (1 . 2) 或 (a . b) ,注意的是点的两边有空格。
这是最简单的复合数据类型,同是它也是其它复合数据类型的基础类型,如列表类型(list)就是由它来实现的。
其中在点前面的值被称为 car ,在点后面的值被称为 cdr ,car和cdr同时又成为取pair的这两个值的过程,如:

列表(list)
列表是由多个相同或不同的数据连续组成的数据类型,它是编程中最常用的复合数据类型之一,很多过程操作都与它相关。下面是在Scheme中列表的定义和相关操作:

make-list用来创建列表,第一个参数是列表的长度,第二个参数是列表中添充的内容;还可以实现多重列表,即列表的元素也是列表,如:(list (list 1 2 3) (list 4 5 6))。
列表与pair的关系
回过头来,我们再看看下面的定义:

由上可见,a本来是我们上面定义的点对,最后形成的却是列表。事实上列表是在点对的基础上形成的一种特殊格式。
再看下面的代码:
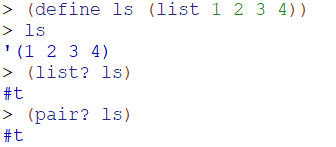
由此可见,list是pair的子类型,list一定是一个pair,而pair不是list。
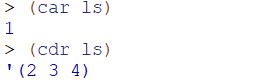
其cdr又是一个列表,可见用于pair的操作过程大多可以用于list。

上面的操作中用到的cadr,cdddr等过程是专门对PAIR型数据再复合形成的数据操作的过程,最多可以支持在中间加四位a或d,如cdddr,caaddr等。
下图表示了由pairs定义形成的列表:
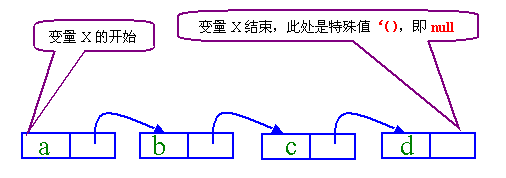
这个列表可以由pair定义为如下形式:(define x (cons 'a (cons 'b (cons 'c (cons 'd '())))))而列表的实际内容则为:(a b c d)由pair类型还可以看出它可以轻松的表示树型结构,尤其是标准的二叉树。
向量(vector)
可以说是一个非常好用的类型 ,是一种元素按整数来索引的对象,异源的数据结构,在占用空间上比同样元素的列表要少,在外观上:

vector是一种比较常用的复合类型,它的元素索引从0开始,至第 n-1 结束,这一点有点类似C语言中的数组。关于向量表(vector)的常用操作过程:

make-vector用来创建一个向量表,第一个参数是数量,后一个参数是添充的值,这和列表中的make-list非常相似。我们可以看出,在Scheme语言中,每种数据类型都有一些基本的和它相关的操作过程,如字符串,列表等相关的操作,这些操作过程都很有规律,过程名的单词之间都用-号隔开,很容易理解。对于学过C++的朋友来说,更类似于某个对象的方法,只不过表现的形式不同了。
类型判断
Scheme语言中所有判断都是用类型名加问号再加相应的常量或变量构成,形如:
(类型? 变量)
Scheme语言在类型定义中有比较严格的界定,如在C语言等一些语言中数字0来代替逻辑类型数据False,在Scheme语言中是不允许的。
以下为常见的类型判断和附加说明:
逻辑型:
(boolean? #t) => #t
(boolean? #f) => #t 因为#t和#f都是boolean类型,所以其值为#t
(boolean? 2) => #f 因为2是数字类型,所以其值为 #f
字符型
(char? #space) => #t
(char? #newline) => #t 以上两个特殊字符:空格和换行
(char? #f) => #t 小写字母 f
(char? #;) => #t 分号 ;
(char? #5) => #t 字符 5 ,以上这些都是正确的,所以返回值都是 #t
(char? 5) => #f 这是数字 5 ,不是字符类型,所以返回 #f
数字型
(integer? 1) => #t
(integer? 2345) => #t
(integer? -90) => #t 以上三个数均为整数
(integer? 8.9) => #f 8.9不整数
(rational? 22/7) => #t
(rational? 2.3) => #t
(real? 1.2) => #t
(real? 3.14159) => #t
(real? -198.34) => #t 以上三个数均为实数型
real? 23) => #t 因为整型属于实型
(number? 5) => #t
(number? 2.345) => #t
(number? 22/7) => #t
其它型:
(null? '()) => #t ; null意为空类型,它表示为 '() ,即括号里什么都没有的符号
(null? 5) => #f
define x 123) 定义变量x其值为123
(symbol? x) => #f
(symbol? 'x) => #t ; 此时 'x 为符号x,并不表示变量x的值
在Scheme语言中如此众多的类型判断功能,使得Scheme语言有着非常好的自省功能。即在判断过程的参数是否附合过程的要求。
比较运算
Scheme语言中可以用<,>,<=,>=,= 来判断数字类型值或表达式的关系,如判断变量x是否等于零,它的形式是这样的:(= x 0) ,如x的值为0则表达式的值为#t,否则为#f。
还有下面的操作:
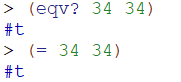
以上两个form功能相同,说明 eqv? 也可以用于数字的判断。
在Scheme语言中有三种相等的定义,两个变量正好是同一个对象;两个对象具有相同的值;两个对象具有相同的结构并且结构中的内容相同。除了上面提到的符号判断过程和eqv?外,还有eq?和equal?也是判断是否相等的过程。
eq?,eqv?,equal?
eq?,eqv?和equal?是三个判断两个参数是否相等的过程,其中eq?和eqv?的功能基本是相同的,只在不同的Scheme语言中表现不一样。
eq?是判断两个参数是否指向同一个对象,如果是才返回#t;equal?则是判断两个对象是否具有相同的结构并且结构中的内容是否相同,它用eq?来比较结构中成员的数量;equal?多用来判断点对,列表,向量表,字符串等复合结构数据类型。

以上操作说明了eq? 和equal? 的不同之处,下面的操作更是证明了这一点:
算术运算
Scheme语言中的运算符有:+ , - , * , / 和 expt (指数运算)其中 - 和 / 还可以用于单目运算,如:

此外还有许多扩展的库提供了很多有用的过程,

除了max,min,abs外,还有很多数学运算过程,这要根据你用的Scheme语言的运行环境有关,不过它们大多是相同的。在R5RS中规定了很多运算过程,在R5RS的参考资料中可以很容易找到。
转换
Scheme语言中用符号组合"->"来标明类型间的转换(很象C语言中的指针)的过程,就象用问号来标明类型判断过程一样。下面是一些常见的类型转换过程:

在Scheme语言中,过程相当于C语言中的函数,不同的是Scheme语言过程是一种数据类型,这也是为什么Scheme语言将程序和数据作为同一对象处理的原因。如果我们在Scheme提示符下输入加号然后回车,会出现下面的情况:
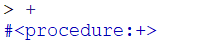
这告诉我们"+"是一个过程,而且是一个原始的过程,即Scheme语言中最基础的过程,在Scheme中内部已经实现的过程,这和类型判断一样,如boolean?等,它们都是Scheme语言中最基本的定义。注意:不同的Scheme语言实现环境,出现的提示信息可能不尽相同,但意义是一样的。
define不仅可以定义变量,还可以定义过程,因在Scheme语言中过程(或函数)都是一种数据类型,所以都可以通过define来定义。不同的是标准的过程定义要使用lambda这一关键字来标识。
Scheme语言中可以用lambda来定义过程,其格式如下:(define 过程名 ( lambda (参数 ...) (操作过程 ...)))
我们可以自定义一个简单的过程,如下:
(define add5 (lambda (x) (+ x 5)))
此过程需要一个参数,其功能为返回此参数加5 的值,如:
(add5 11) => 16
下面是简单的求平方过程square的定义:
(define square (lambda (x) (* x x)))
在Scheme语言中,也可以不用lambda,而直接用define来定义过程,它的格式为:(define (过程名 参数) (过程内容 …))
如下面操作:
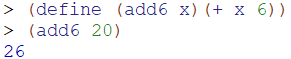
再看下面的操作:

上面定义的过程fun有三个参数,其中第一个参数proc也是一个操作过程(因为在Scheme语言中过程也是一种数据,可以作为过程的参数),另外两个参数是数值,所以会出现上面的调用结果。

继续上面操作,我们定义一个过程add,将add作为参数传递给fun过程,得出和(fun + 100 200)相同的结果。
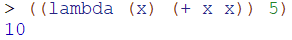
上面的 (lambda(x) (+ x x)) 事实上是简单的过程定义,在后面直接加上操作参数5,得出结果10,这样实现了匿名过程,直接用过程定义来操作参数,得出运算结果。
通过上面的操作,相信你已初步了解了过程的用法。 既然过程是一种数据类型,所以将过程作为过程的参数是完全可以的。以下过程为判断参数是否为过程,给出一个参数,用 procedure? 来判断参数是否为过程,采用if结构(关于if结构见下面的介绍):

上面的过程就体现了Scheme语言的参数自省(辨别)能力,'0'是数字型,所以返回notaprocedure;而'+'是一个最基础的操作过程,所以返回isaprocedure。
在Scheme语言中,过程定义也可以嵌套,一般情况下,过程的内部过程定义只有在过程内部才有效,相当C语言中的局部变量。
如下面的代码的最终结果是50:

此时过程add只在fix过程内部起做用,这事实上涉及了过程和变量的绑定,可以参考下面的关于过程绑定(let,let* 和letrec)的介绍。
过程是初学者难理解的一个关键,随着过程参数的增加和功能的增强,过程的内容变得越来越复杂,小括号也会更多,如果不写出清晰的代码的话,读代码也会成为一个难题。

本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册