
2024年如何为ANSYS CFD求解器选择硬件?考虑所有预算,包括从笔记本电脑到集群!
注意:本文撰写于2023年12月,但这是一个不断变化的领域,各种信息数据有可能滞后。原文地址:https://www.computationalfluiddynamics.com.au/how-to-approach-hardware-selection-in-2024/
”
LEAP的工程师经常会收到来自各行各业的客户咨询,这些客户在购买新硬件时,希望在成本与最佳求解器性能之间找到平衡。以下建议主要基于LEAP近期特别针对CFD工作领域(Fluent)的经验。如果系统设计得当,FVM代码能够实现极佳的扩展性,其他工具如ANSYS Mechanical或Electromagnetics也有类似要求,但与Fluent相比存在一些显著差异/例外:
-
FEA代码通常不如FVM代码扩展性好,不应期望看到如下图所示的同等程度加速效果。 -
Mechanical和EM求解过程中会执行大量I/O操作,因此,系统必须配备高速存储设备(如NVMe SSD)作为临时/项目目录。 -
ANSYS EM(HFSS和Maxwell 3D)需要的内存容量远超CFD。 -
截至2023 R2版本,ANSYS Maxwell在Intel平台上表现最佳,其得益于更广泛的优化数学库支持。
优化求解器性能的一般建议:
-
内存带宽是大多数情况下的关键性能指标。充分利用系统中每个可用的内存通道。 -
强烈建议使用基于DDR5的新平台,而非DDR4。除非供应商限制严格必要,否则不建议购买DDR4系统。 -
高的基础时钟速度至关重要——不要购买高核心数但低功耗的CPU。 -
ANSYS求解器应始终在物理核心上运行,而非单个线程(通常建议在专用工作站/服务器上关闭多线程)。 -
确保工作目录和临时位置位于高速NVMe存储设备上。 -
为预处理/后处理配备的独立GPU。

1 小型系统
用于在4核上求解的笔记本/台式机,目标是获得在4个核心上可能达到的最大性能。
笔记本电脑的主要考虑因素:
-
选择配备充足散热功能的机箱(轻薄超极本风格笔记本除外)。 -
使用以 H为后缀的CPU——这些是高功率版本,通常TDP为35W或更高。 -
6000系列的AMD支持DDR5——优选7040/8040系列以获得Zen 4核心(如7940HS)。 -
Intel从第12代开始支持DDR5。 -
推荐至少32GB内存,最好64GB以支持大规模作业运行。 -
NVMe存储——至少1TB,以容纳操作系统、软件和项目数据。 -
独立GPU用于显示/可视化目的(首选NVidia——ANSYS工具中支持更广泛)。
对于游戏/消费级4核以上配置:
-
游戏类型的系统通常非常合适。 -
高时钟速度(base>4 GHz,turbo>5 GHz)。 -
DDR5内存(速度越快越好——例如6000 MHz)。 -
NVMe存储——至少1TB以容纳操作系统、软件和项目数据。 -
用于显示/可视化目的的独立GPU(首选NVidia——ANSYS工具中支持更广泛)。
在此类别中AMD 和 Intel 均有合适的选择:
-
AMD Ryzen 7000系列(Zen 4)。 -
AMD 3D V-cache CPU(7800X3D, 7950X3D)特别适合CFD工作负载,因其能从大缓存池中获益良多。 -
Intel第12代、第13代和第14代Core系列。
2 中小型系统
适用于约12个处理器核心的桌面/工作站。
尽管使用游戏类型系统可能很诱人,但这里有一些新的考虑因素:
-
最好避免使用具有性能和效率核心的混合处理器架构——希望仿真能在12个相同的高性能核心上运行。因此,通常不推荐使用Intel Core系列处理器(如Intel 14900K,拥有8个性能核心和16个效率核心)。 -
需要考虑内存带宽。游戏/消费级CPU只有2个内存通道,这可能在将模拟任务分配到12个核心时造成瓶颈(每个通道6个核心)。通常更倾向于将核心/通道比率限制在4:1,尽管DDR5提供的高带宽在一定程度上缓解了这个问题,因此扩展到6:1仍然是可行的。
基于上述情况,建议选择使用AMD Ryzen 7000系列CPU,配备>=12个核心和~6000 MHz的DDR5(例如7950X),或升级到专用工作站设备(Intel Xeon-W,AMD Threadripper)。
对于一款12核以上的游戏/消费级AMD Ryzen配置:
-
7900X(12核心)或7950X(16核心)。 -
7950X3D也是一个选项,尽管额外的缓存仅位于8个核心上——这可能导致类似于Intel P/E核心的负载均衡问题(未测试!)。 -
DDR5内存(速度越快越好——例如6000 MHz),通常64GB是合适的——注意,超过此容量的内存可能会因每个通道运行多个DIMM时的稳定性要求而导致速度降低。 -
NVMe存储——至少1TB以容纳操作系统、软件和项目数据。 -
考虑第二块存储设备来处理大量项目文件。 -
用于显示/可视化目的的独立GPU(首选NVidia——ANSYS工具中支持更广泛)。
对于专用的12核以上工作站级配置:
-
AMD Threadripper: -
非Pro版本适合,因为4个内存通道足以应对这些相对较低的核心数。 -
7000系列(DDR5)在2023年末发布,否则使用5000系列(DDR4)。 -
Intel Xeon-W: -
首选Sapphire Rapids(即2023年及以后型号)。 -
优先考虑更高的基础时钟速度。 -
较旧的DDR4系统也可以,因为有更多通道来弥补较低的速度,但DDR5仍然是强烈推荐的选择。 -
确保至少使用4个内存通道: -
即在主板上使用4个独立的内存DIMM。 -
如果想使用64GB的内存,确保使用4x 16GB的DIMM。 -
同样对于128GB,使用4x 32GB。 -
NVMe存储——至少1TB以容纳操作系统、软件和项目数据。 -
考虑第二块存储设备来处理大量项目文件。 -
考虑中端NVidia Quadro GPU(例如RTX A4000)以获得更好的大型模型显示性能。在特定情况下也可以用于求解器加速,甚至在使用Fluent的GPU求解器时完全取代CPU。
3 中型系统
适用于约36个求解器核心的工作站。与上一节工作站级配置类似的要求,但有一些修改。
对于专用的36核以上工作站级配置:
-
AMD Threadripper Pro: -
不要使用非Pro版本——这些只有4个内存通道。 -
7000系列(DDR5)在2023年末发布,否则使用5000系列(DDR4)。 -
Intel Xeon-W: -
首选Sapphire Rapids(即2023年及以后型号)。 -
有很多选项,确保优先考虑更高的基础时钟速度。 -
也可以使用服务器级部件(例如Xeon Gold/Platinum,AMD Epyc)。 -
确保至少使用8个内存通道(AMD Epyc 9004系列为12个): -
即在主板上使用8个独立的内存DIMM。 -
如果想使用128GB的内存,确保使用8x 16GB的DIMM。 -
对于256GB,使用8x 32GB。 -
也可以使用较旧的DDR4系统,因为有更多通道来弥补较低的速度,但DDR5仍然是强烈推荐的选择。如果只能使用较旧的DDR4平台(特别是Intel),建议使用双CPU设置——这样可以将可用内存通道从6个增加到12个。这需要Xeon Gold/Platinum(或AMD Epyc),而不是工作站级的W系列(或AMD Threadripper)。 -
NVMe存储——至少1TB以容纳操作系统、软件和项目数据。 -
考虑第二块存储设备来处理大量项目文件。 -
考虑中端NVidia Quadro GPU(例如RTX A4000)以获得更好的大型模型显示性能。在特定情况下也可以用于求解器加速,甚至在使用Fluent的GPU求解器时完全取代CPU(见下文的专用部分)。
4 大型系统
适用于约128+核心的工作站/服务器/集群。
多CPU系统需要服务器级部件。更大的核心数将需要具有高速互连的集群节点。目标是确保总系统内存带宽足以支持不断增加的核心数。
-
AMD Epyc:
-
强烈推荐9004系列(Genoa)。每个CPU有12个DDR5通道,最多可支持96个核心;然而由于内存带宽限制,不建议使用超过64核心的型号。 -
较旧的7001/2/3系列每CPU有8个DDR4通道;由于内存带宽限制,不建议使用超过32核心的型号。 -
优先考虑高基础时钟速度的型号。 -
使用3D V-Cache“X”系列部件可以获得显著的性能提升,这些部件具有额外的L3缓存。 -
Intel Xeon Platinum:
-
强烈推荐Sapphire Rapids(第四代)。每CPU有8个DDR5通道,最多可支持60个核心;然而,由于内存通道较少,性能预计在比AMD 9004系列更低的核心数时下降。 -
较旧的系列有8个DDR4通道,最多可支持40个核心。 -
优先考虑高基础时钟速度的型号。 -
使用Max系列部件可以获得显著的性能提升,这些部件具有片上HBM内存。 -
确保插满每一个可用的内存通道:
-
对于上一代Inte:每个CPU 6个DIMM(总共12个)。 -
对于当前一代Intel或上一代AMD:每个CPU 8个DIMM(总共16个)。 -
对于AMD 9004系列:每个CPU 12个DIMM(总共24个)。

最大化性价比,最高可达~128核:
-
构建一台双CPU的单机箱机器(一些Intel处理器可以用于四CPU配置,但由于每个CPU之间的通信速度降低,我们不推荐这种配置)。 -
基于AMD 9004或Intel Sapphire Rapids的新一代DDR5系统可以扩展到100个以上的核心。 -
较旧的DDR4系统将被限制在总共约64个核心。我们不推荐走这条路,因为可能无法最大化3个ANSYS HPC软件包的价值。
最大化绝对性能:
-
构建一个多节点集群。 -
选择较低核心数的CPU以最大化每个核心的内存带宽(最好是每个核心10 GB/s或更高)。 -
利用高级技术,如AMD 3D V-cache或Intel HBM。 -
使用高速互连,如InfiniBand,允许每个节点之间以100 GB/s以上的速度通信。
5 AMD 3D V-Cache 和 Intel HBM
这些技术的最终目标都是提高内存带宽受限应用的性能。AMD的方法是通过在核心复合体(CCD)上堆叠额外的芯片,将L3缓存容量增加三倍——最新版本现在每个CPU的缓存超过1 GB。Intel的方法类似于增加一个大型L4缓存(即在L3缓存和DRAM之间增加一个额外的层),每个CPU的容量可达64 GB。
AMD 3D V-Cache
单节点性能可显著提升——多项基准测试(注:前代7003X系列)显示速度提升10%至30%,其中一项甚至高达80%:
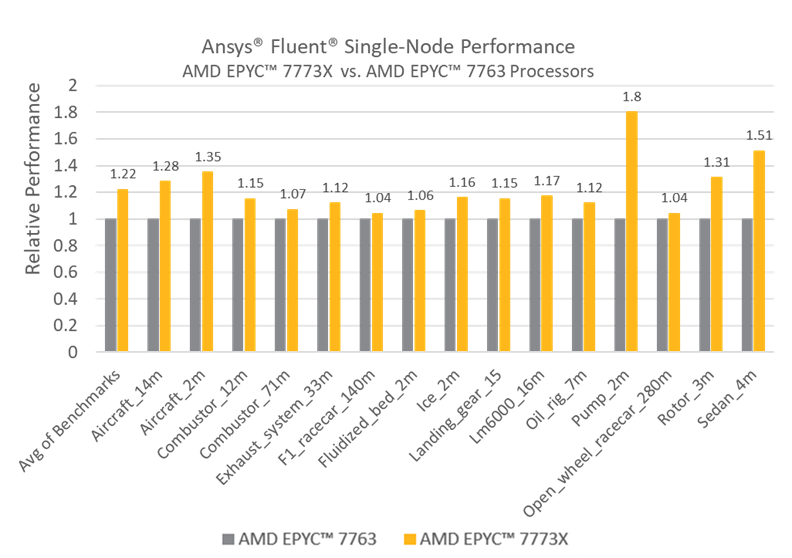
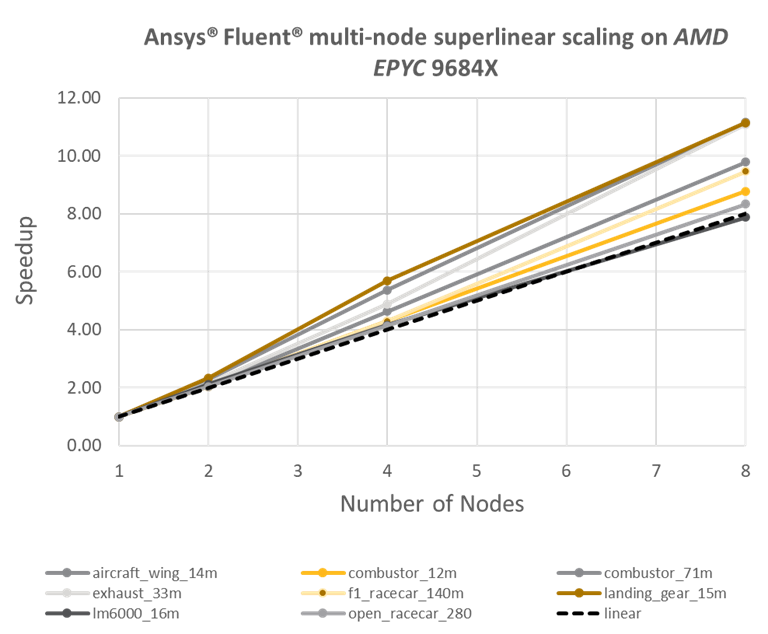
多节点性能可能表现出超线性扩展——即加速因子可能超过节点数量。随着系统中添加更多节点,总缓存容量相应增加,因此更高比例的模拟能够驻留在缓存而非DRAM中——以下示例显示了一个由8个节点组成的系统实现了11倍的加速:
Intel HBM (Xeon Max)
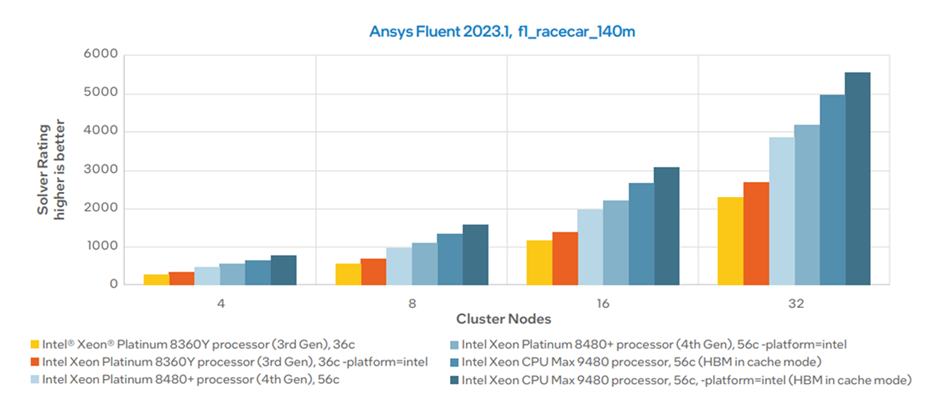
高带宽内存(HBM)是一种堆叠式DRAM技术,具有非常宽的总线——每堆栈1024位,相比之下DDR5通道为64位。英特尔Xeon Max系列CPU采用4个16GB HBM2e堆栈,总容量达64GB,运行速度为1.22 TB/s;结合8个标准DDR5内存通道提供的307.2 GB/s。在英特尔进行的以下基准测试中,HBM处理器(9480)显示出比常规型号(8480+)高出超过30%的性能:
6 额外GPU求解器注意事项
GPU可以为优化后在高度并行环境中运行的代码提供显著的速度提升。粒子型求解器(如LBM、DEM、SPH等)或光线追踪求解器(如SBR+)非常适合使用GPU,因为代码的并行化非常简单;然而,使用传统的CFD和FEA方法(如FVM和FEM)实现这一点则要困难得多。
ANSYS最近为Fluent发布了一个原生的多GPU(FVM)求解器,目前支持滑移网格、尺度解析湍流、共轭传热、非刚性反应流和适度可压缩性等特性。许多基准测试显示,一台高端GPU(如NVidia A100)的性能可以与约500个CPU核心相当——从而显著节省硬件成本,并使用户能够自行运行大型模拟,而不必依赖外部集群或云计算。
ANSYS Rocky是另一个适合使用GPU的工具。Rocky主要是一个DEM求解器,能够处理涉及数百万颗粒的复杂固体运动;同时还有一个SPH求解器,用于处理自由表面流体的运动。
Fluent和Rocky对GPU规格的要求相似:
-
需要使用NVidia GPU,因为其代码是基于CUDA编写的(尽管AMD支持正在开发中)。 -
内存带宽是关键——配备HBM的模型可以提供比GDDR6(最高1 TB/s)显著更高的带宽(多TB/s)。 -
许可证基于GPU上的流多处理器(SM)数量,而不是CPU上的核心数量。注意,与CPU不同,启动模拟时会使用GPU上的所有SM——因此需要确保许可证级别足以使用整个显卡。 -
在某些情况下(主要是Rocky中的非球形颗粒),可能需要高双精度(FP64)吞吐量的GPU。请注意,虽然Fluent通常在双精度模式下使用,但理论上的FP64吞吐量并不是一个非常重要的性能指标——主要的瓶颈仍然是内存带宽。这意味着即使FP64吞吐量与FP32相比为1:32(甚至1:64)的游戏GPU,只要内存带宽足够,仍然可以在双精度模拟中表现出色。 -
足够的VRAM以使整个模拟在GPU上进行,而不需要系统内存。
简而言之:
-
为了获得最佳性能,考虑使用NVidia A100 / H100或类似产品(配备高带宽的HBM,以及高双精度吞吐量)。 -
对于预算有限的硬件和许可证,选择内存带宽高、内存容量大但SM数量少的显卡。例如,NVidia RTX A5000(24 GB,768 GB/s,64个SM)。 -
对于Rocky中的非球形颗粒,选择具备良好FP64吞吐量的显卡。
6 操作系统
绝大多数ANSYS工具可以在Windows或Linux上运行。出于多种原因,通常建议在本地Windows机器上进行预处理和后处理:
-
ANSYS SpaceClaim和Discovery目前仅在Windows上可用。 -
Windows上的显示驱动程序往往更成熟/稳健。 -
如果通过远程连接操作大型模型,输入延迟可能成为一个问题。 -
在服务器上进行预处理/后处理可能会浪费计算资源——通常希望尽可能保持100%的求解器运行时间。
Windows也适用于小型到中等大小的机器(例如,约32核的工作站)上的求解,但我们通常建议使用专门的Linux服务器进行更大规模的求解机器和集群——特别是如果需要多用户环境(例如,排队系统等)。
(完)
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册