
Marker是一款能够将PDF文档转换为Markdown格式文档的开源工具。
想要将PDF文件的内容转化为Markdown格式,以前采用复制粘贴的方式,对于文本类型的文件还勉强能够对付,但对于专业文献那种包含有大量的公式、图形图表的文档就无能为力了。而对于图片形式的文档,那就更是没办法弄了。
好在有了Marker。
github仓库地址:https://github.com/VikParuchuri/marker
”
1 Marker是什么
1.1 Marker
Marker 快速而准确地将 PDF 转换为 Markdown 格式。
-
广泛文档支持(特别适合书籍和科学论文) -
全语言支持 -
移除页眉、页脚及其它冗余元素 -
格式化表格与代码块 -
提取并随 Markdown 保存图像 -
大多数公式转换为 LaTeX -
支持 GPU、CPU 或 MPS 运行
1.2 工作原理
Marker 是一系列深度学习模型构成的处理流程:
-
提取文本,必要时进行 OCR(光学字符识别) -
检测页面布局并确定阅读顺序 -
清理并格式化每个内容块 -
合并内容块并对全文进行后处理
1.3 局限性
由于 PDF 格式的复杂性,Marker 有时可能无法完美转换。以下是已知的一些局限性:
-
Marker 无法保证将所有公式完全转换为 LaTeX。这是因为它需要先识别再转换。 -
表格格式化不一定总是完全正确——文本可能会出现在错误的列中。 -
空白与缩进可能无法完全保留。 -
并非所有行或段落都能被正确连接。 -
该工具在数字化 PDF(无需大量 OCR 处理)上的表现最佳。它侧重于速度优化,仅限于修正错误时使用有限的 OCR 功能。
2 前置安装
Marker基于深度学习网络,在使用之前需要在本机构建运行环境。
2.1 安装CUDA
marker可以使用GPU进行加速。
-
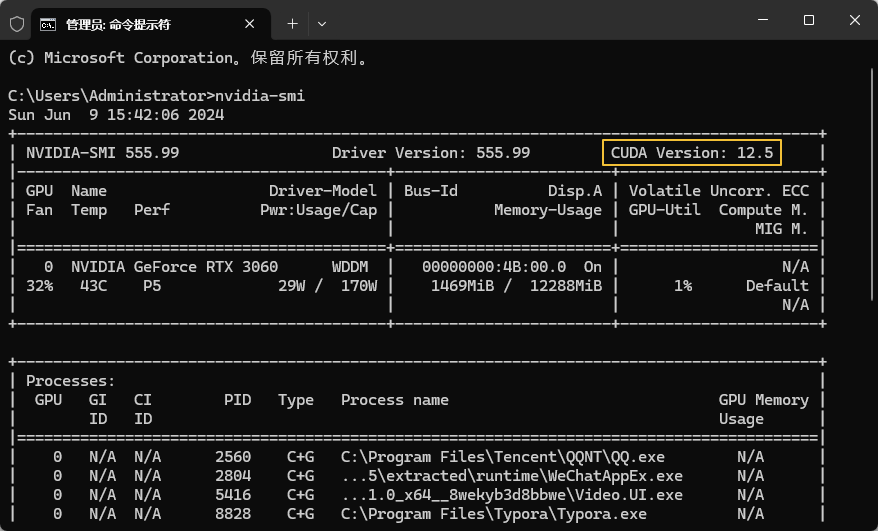
先判断本机显卡能支持的最高CUDA版本。在命令提示符中输入 nvidia-smi,如下图所示,可以看到本机显卡驱动能支持的CUDA版本为12.5。
-
安装CUDA
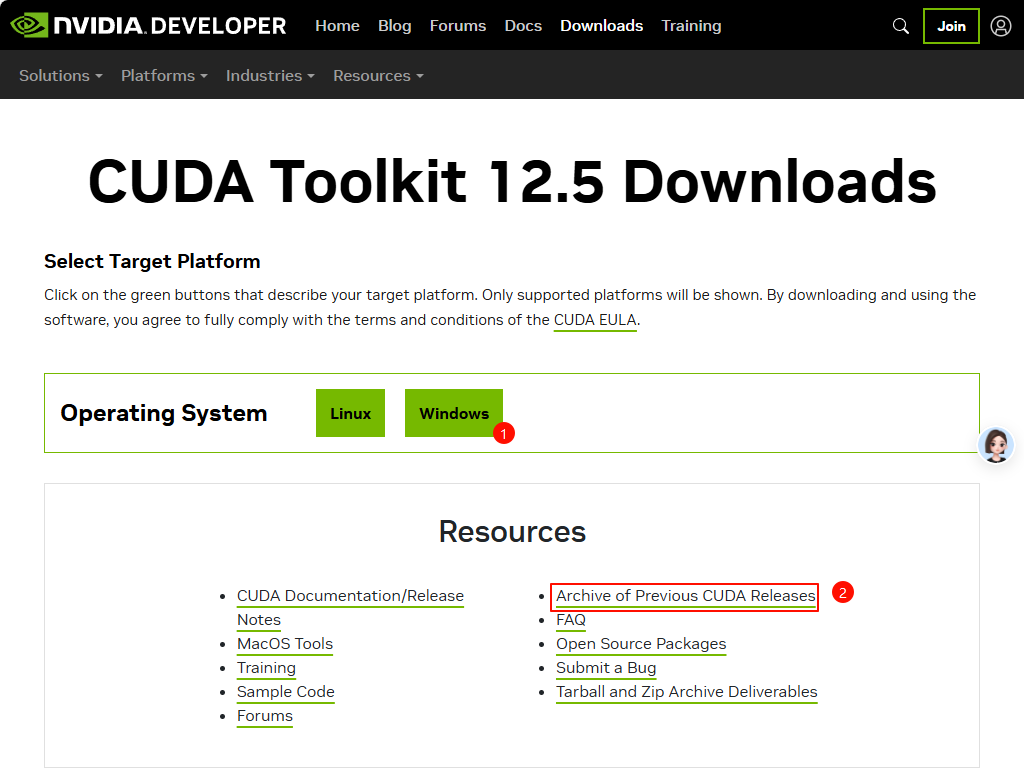
进入下载网址:https://developer.nvidia.com/cuda-downloads 。当前最新版本为12.5。若安装12.5版本的话,可以点下图中1所示的操作系统选择按钮。若需要安装老版本,可以点下图中2所示的链接。
如下图所示,根据本机情况选择合适的版本进行下载。
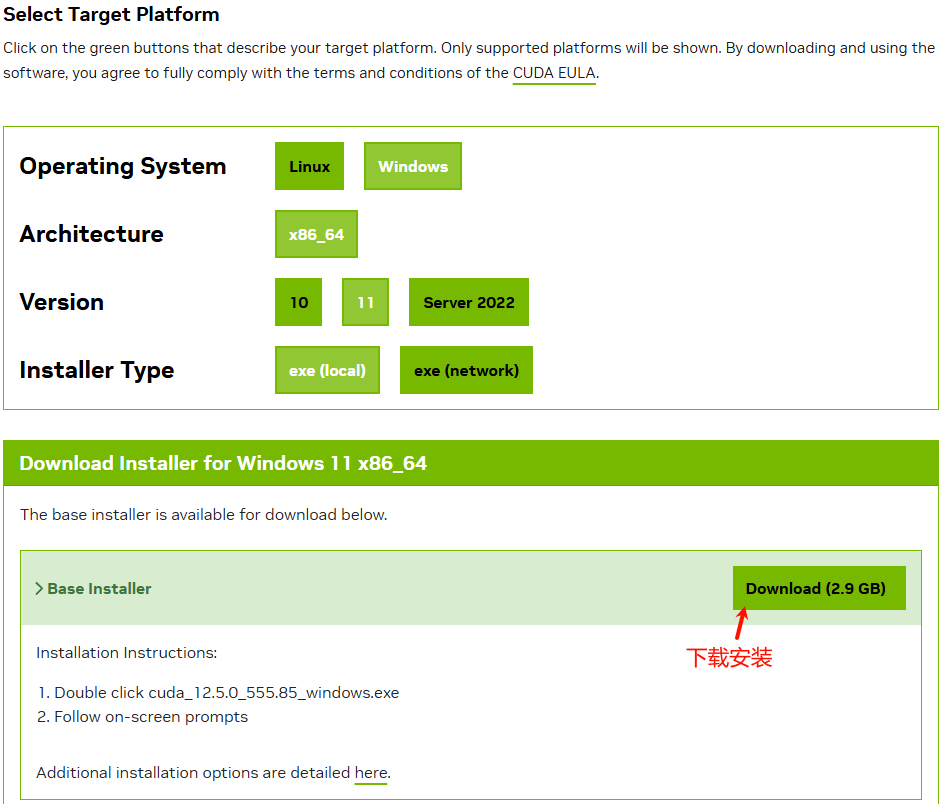
下载后直接双击按默认安装即可。
注:具体安装过程可参阅:https://blog.csdn.net/tyyhmtyyhm/article/details/136840339
”
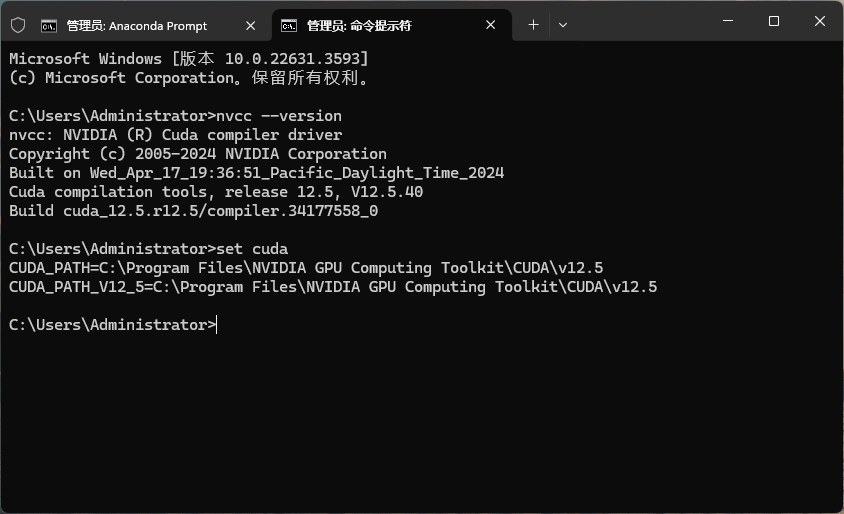
安装完毕后在命令行窗口输入nvcc --version或set cuda,若如下图所示显示,则表示CUDA安装成功。
2.2 安装cuDNN
cuDNN是一个深度学习加速库,一并安装了。
下载地址:https://developer.nvidia.com/cudnn-downloads
”
如下图所示,打开网址后,根据本机情况选择合适的版本进行下载。
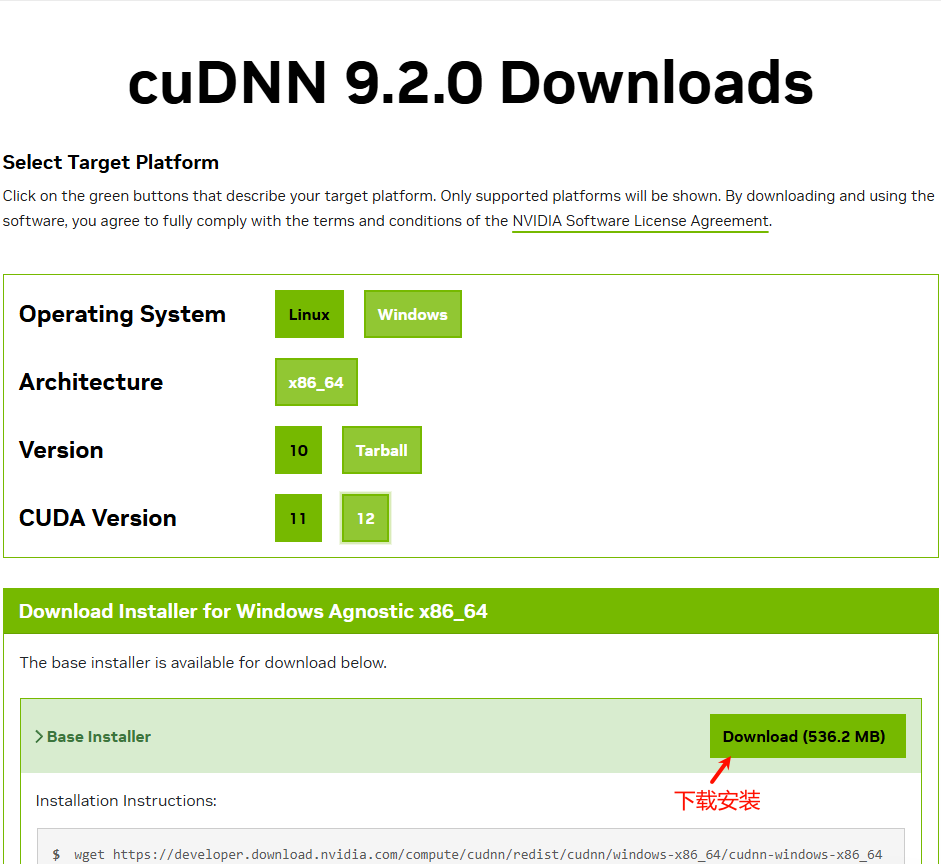
将下载的cuDNN压缩文件解压后放到CUDA的安装路径下(如C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.5)即可。
cuDNN安装完毕后可以采用下面的方法进行验证:
-
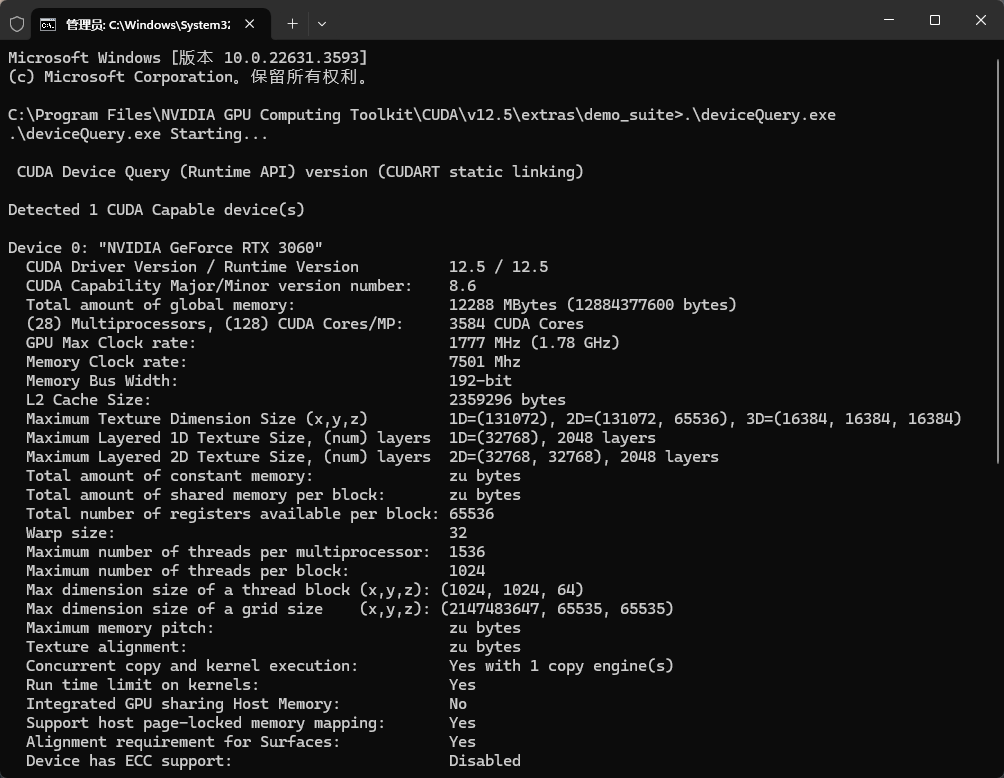
从命令行进入CUDA安装目录下的 CUDAv12.5extrasdemo_suite文件夹。 -
输入 .deviceQuery.exe命令,观察窗口输出结果。
若显示如下图所示,则表示cuDNN安装成功。
2.3 安装Anaconda
Anaconda并非必须,只是为了后续使用方便而已。
官网下载地址:https://www.anaconda.com/download/
”
下载后直接安装即可。
注:如果嫌anaconda个头太大不想安装的话,也可以安装miniforge:https://github.com/conda-forge/miniforge/releases
”
anaconda安装完毕后可以创建虚拟环境。
-
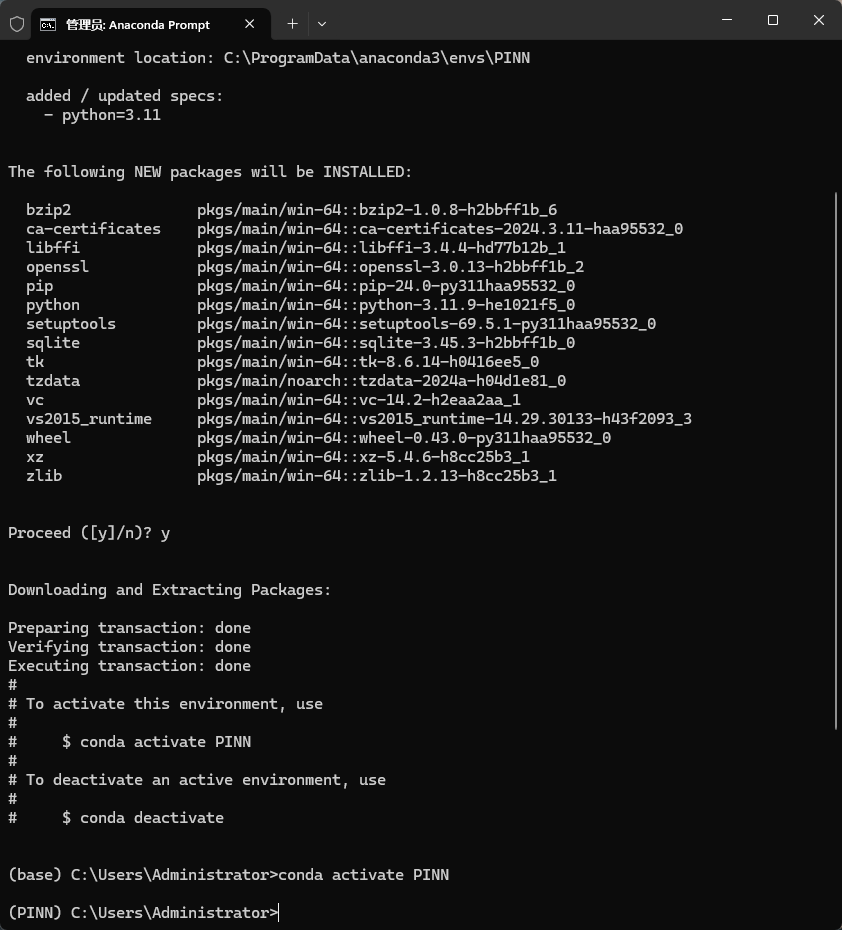
从开始菜单启动 Anaconda Prompt,输入下面的命令并激活
conda create -n PINN python=3.11
conda activate PINN
如下图所示。
Anaconda Prompt窗口不要关闭,后面还要接着用。
2.4 安装pytorch
运行Marker需要借助于pytorch。
官网地址:https://pytorch.org/
”
-
打开网址 https://pytorch.org/get-started/locally/,按照本机配置,拷贝安装命令。

-
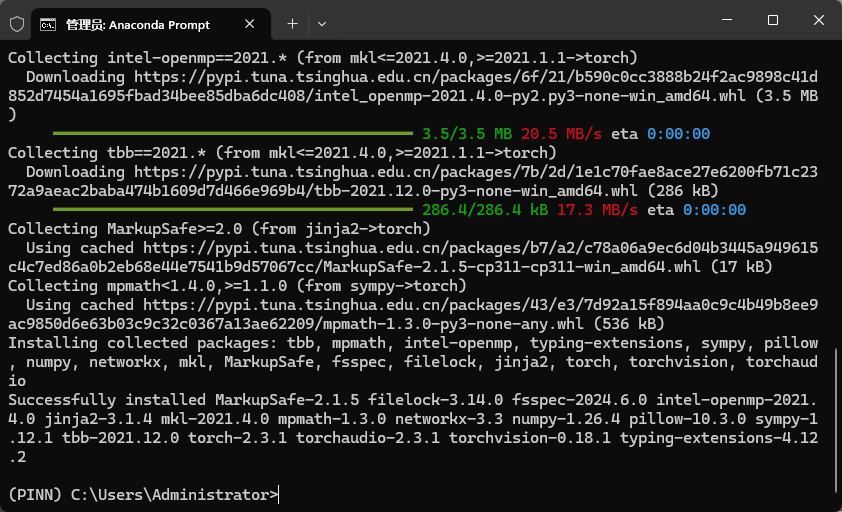
从开始菜单打开Anaconda Prompt,粘贴拷贝的安装命令。如果下载速度很慢,可以在后面添加国内镜像源,如下所示添加清华源
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 -i https://pypi.tuna.tsinghua.edu.cn/simple
如下图所示。

安装完毕后如图所示。
2.5 安装Marker
Marker的安装非常简单,输入下面的命令即可:
pip install marker-pdf
如下图所示。
如果下载过慢,可以使用下面的命令:
pip install marker-pdf -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完毕后如图所示。
3 Marker使用
3.1 使用方法
首先,进行一些配置:
-
查看 marker/settings.py中的设置项。可以使用环境变量覆盖任何设置。文件完整路径为:C:ProgramDataanaconda3envsPINNLibsite-packagesmarkersettings.py -
PyTorch 设备可以被自动检测,但也可以手动指定。例如使用 TORCH_DEVICE=cuda来指定CUDA设备。 -
如果使用GPU,根据GPU显存设置 INFERENCE_RAM。例如,若有16GB的显存,应设置INFERENCE_RAM=16。 -
根据文档类型的不同, marker在每个任务上的平均内存使用量可能会略有变化。如果发现任务因GPU内存不足而失败,可以通过调整VRAM_PER_TASK来优化这一设置。 -
默认情况下, marker使用surya进行OCR识别。surya在CPU上运行较慢,但比Tesseract更准确。如果需要更快的OCR速度,可以将OCR_ENGINE设置为ocrmypdf。请注意,这还需要安装额外的依赖(见前述说明)。如果完全不需要OCR功能,可以将OCR_ENGINE设置为None。
3.2 单文件转换
在命令行中输入以下命令来转换单个文件:
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10 --langs English
-
--batch_multiplier参数用于根据额外的VRAM量调整默认批次大小。数值越大,消耗的VRAM越多,但处理速度也越快。默认值为2。默认批次大小大约占用3GB的VRAM。 -
--max_pages参数限制了要处理的最大页数。省略此参数将转换整个文档。 -
--langs参数是一个由逗号分隔的列表,用于指定文档中所含的语言,以便进行OCR识别。
请确保 DEFAULT_LANG 设置适合文档需求。支持的OCR语言列表可以在Surya项目的这个文件中找到。如果需要更多语言,当将 OCR_ENGINE 设置为 ocrmypdf 时,可以使用Tesseract支持的任何语言。如果不进行OCR,marker 可以处理任何语言的文档。
3.3 批量转换文件
通过以下命令可以批量转换位于某个文件夹下的多个PDF文件:
marker /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000
-
--workers表示同时转换的PDF文件数量。默认值为1,但可以增加该数值以提高吞吐量,不过会相应增加CPU和GPU的使用率。如果使用GPU,实际并行度不会超过INFERENCE_RAM/VRAM_PER_TASK的计算结果。 -
--max指定要转换的最大PDF文件数量。省略此选项将转换文件夹中的所有PDF。 -
--min_length是从PDF中提取的字符最小数量,达到此数量的PDF才会被纳入处理考虑。如果需要处理大量PDF,建议设置此参数以避免对主要为图像的PDF进行OCR处理(这会降低整体处理速度)。 -
--metadata_file是一个可选参数,用于指定包含PDF元数据的JSON文件路径。如果提供此文件,程序将利用这些元数据为每个PDF设定语言;如果不提供,则使用DEFAULT_LANG配置的默认语言进行处理。格式为:
{
"pdf1.pdf": {"languages": ["English"]},
"pdf2.pdf": {"languages": ["Spanish", "Russian"]},
...
}
在使用多GPU环境下批量转换多个文件时,您可以依据特定的环境变量来调整设置,以优化性能和资源分配。下面是具体的操作指导:
3.4 多GPU环境下批量转换文件
执行以下命令以在多块GPU上并行处理多个PDF文件:
MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
-
METADATA_FILE是指向包含PDF元数据的JSON文件路径的可选参数。元数据格式如上所述。 -
NUM_DEVICES指定要使用的GPU数量,至少应为2。 -
NUM_WORKERS设置在每块GPU上运行的并行进程数。单个GPU的并行度不会超过由INFERENCE_RAM / VRAM_PER_TASK计算出的值。 -
MIN_LENGTH定义了PDF中必须提取的最小字符数,低于此阈值的PDF将不进行处理,有助于避免大部分为图像的PDF减缓整体处理速度。
请注意,上述环境变量是针对特定脚本设定的,不能在 local.env 文件中设置。
3.5 常见问题
如果遇到不符合预期的工作情况,以下是一些可能有用的设置和排查步骤:
-
OCR_ALL_PAGES- 将此设置为true强制对所有页面进行OCR。当表格布局默认未被正确识别或存在乱码时,这将非常有用。 -
TORCH_DEVICE- 设置此变量以强制marker使用特定的PyTorch设备进行推理。 -
OCR_ENGINE- 可以设置为surya或ocrmypdf,根据需要选择OCR引擎。 -
DEBUG- 将此设置为True可在转换多个PDF时显示Ray日志,有助于调试。 -
确认已正确设置了语言,或提供了元数据文件。 -
若遇到内存不足错误,尝试减少工作进程数(增加 VRAM_PER_TASK设置),或者将长PDF拆分成多个文件处理。
通常,如果输出不符合预期,首先尝试对PDF进行OCR是一个好的起点,因为并非所有PDF都嵌入了良好的文本或边界框信息。
4 大模型下载
Marker工作需要有AI模型支持,直接运行时会自动从hanggingface下载模型,受网络限制,很多时候模型是下不下来的。此时可以使用抱脸镜像站hf-mirror。
采用采用以下方式操作:
-
安装依赖
pip install -U huggingface_hub
-
设置环境变量(win系统使用setx,linux系统使用export)
setx HF_ENDPOINT https://hf-mirror.com
重启电脑使得环境变量生效。
此时再运行命令会自动下载模型文件。
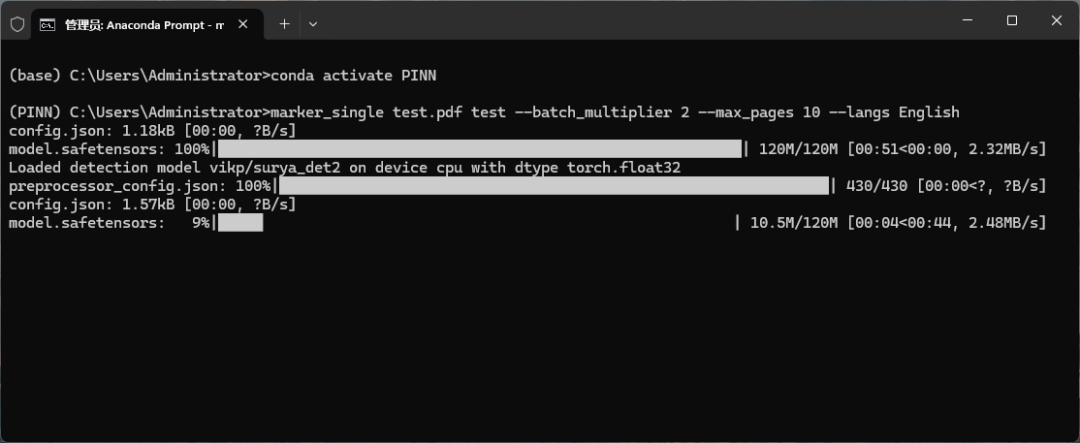
等模型下载完了后,再执行转换程序就会自动加载模型进行转换操作了。
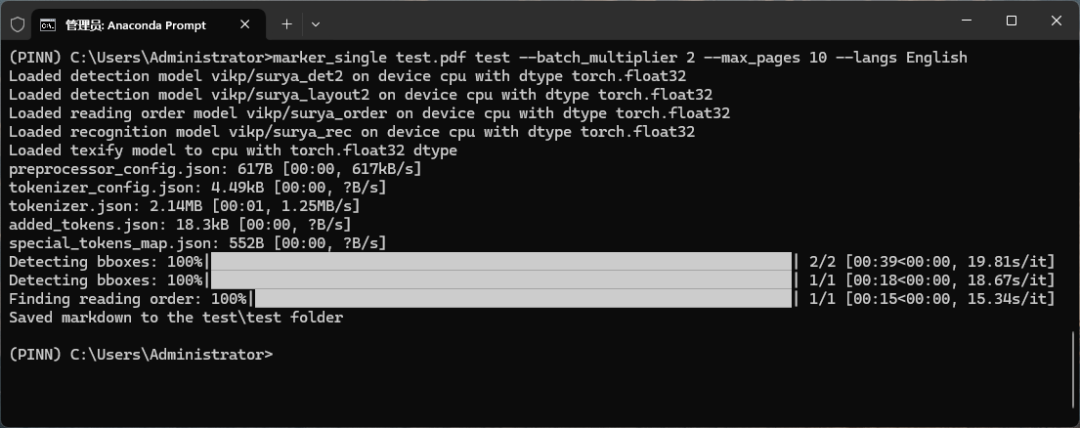
如上面的命令转换完毕后会在文件夹下生成markdown文件。打开看一下效果其实还不错。
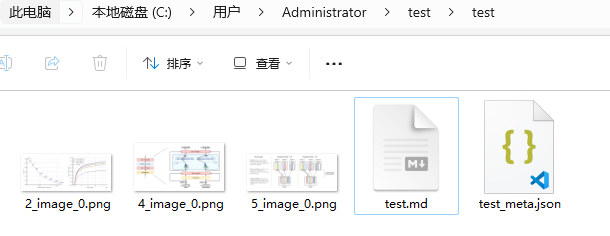
Marker默认使用CPU,若要使用GPU,则可打开文件C:ProgramDataanaconda3envsPINNLibsite-packagesmarkersettings.py进行设置。
(完)
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册