
整个过程需要准备三个软件:
-
Ollama。用于运行本地大模型。如果使用闭源大模型的API,则不需要安装Ollama。 -
Docker。用于运行AnythingLLM。 -
AnythingLLM。知识库运行平台,提供知识库构建及运行的功能。
1 安装Ollama
-
下载Ollama(网址:https://ollama.com/download)
下载后直接安装,然后启动命令行窗口输入命令加载模型。命令可以通过点击官网Models后,搜索并选择所需要的模型后查看。
-
搜索框输入 qwen
-
选择模型后,拷贝对应的命令
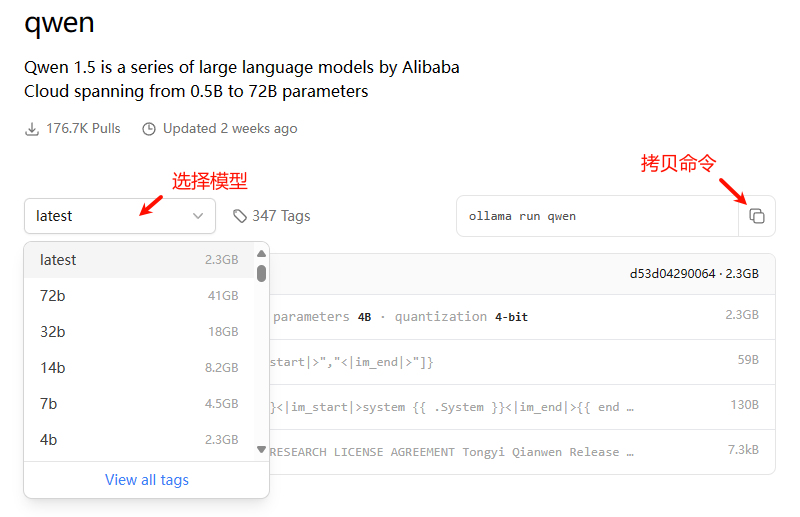
注:Ollama支持加载运行GGUF格式的大模型,这个自行查看官网。
”
-
启动命令行窗口,拷贝命令并运行,若是第一次运行,Ollama会自动下载模型并启动模型。如本机上已安装了qwen:14b模型,则输入命令后会直接启动此模型。
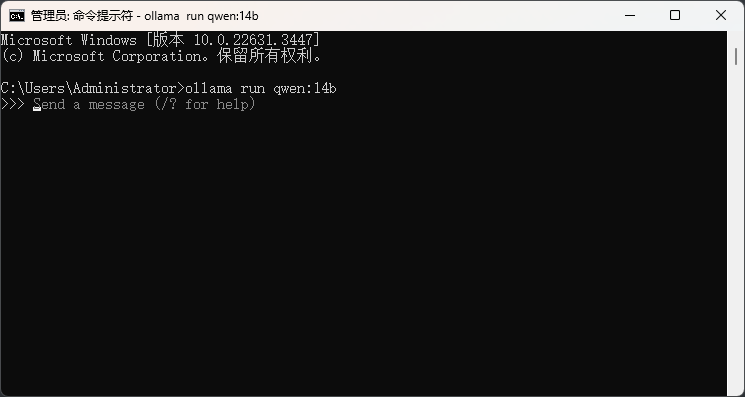
至此,Ollama安装完毕。
2 安装Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的操作系统的机器上,从而实现虚拟化。
-
安装Docker Desktop(下载网址:https://www.docker.com/products/docker-desktop/)
下载后直接双击安装即可,Docker的安装过程非常简单,没有什么参数需要设置,一路next即可。
3 安装AnythingLLM
AnythingLLM可以在Docker上安装。
-
启动Docker Desktop。第一次启动可能需要注册账号,也可以直接使用google、github账号登陆。 -
点击顶部的搜索框或输入快捷键 Ctrl + K打开搜索窗口,输入anythingllm进行搜索,如下图所示,点击 Pull 按钮拉取镜像
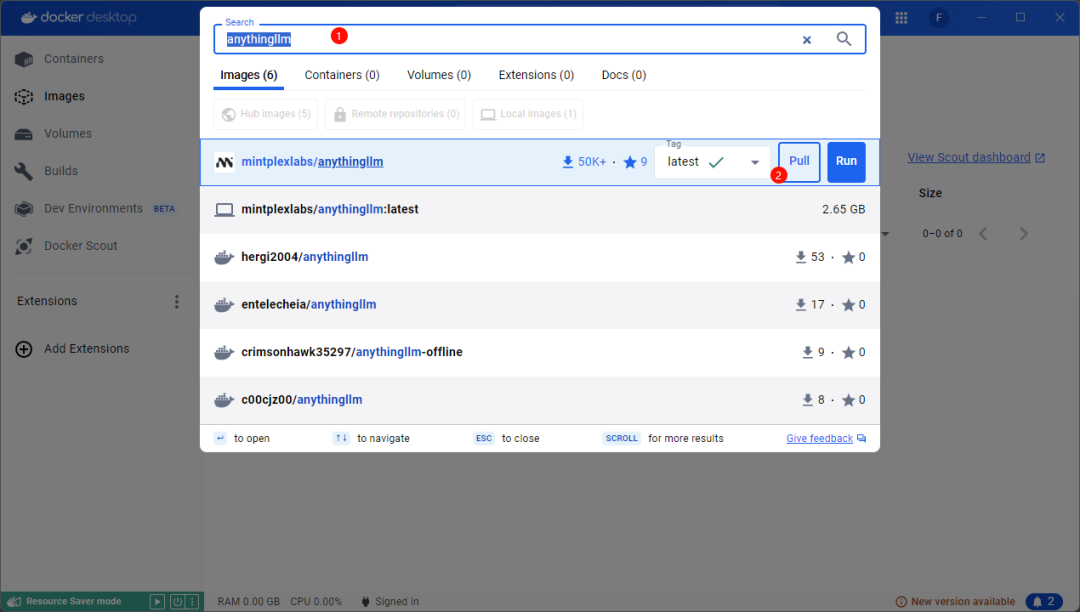
-
模型拉取完毕后,点击 Images 并在右侧的镜像列表中点击anythingllm后的 Run 按钮启动镜像
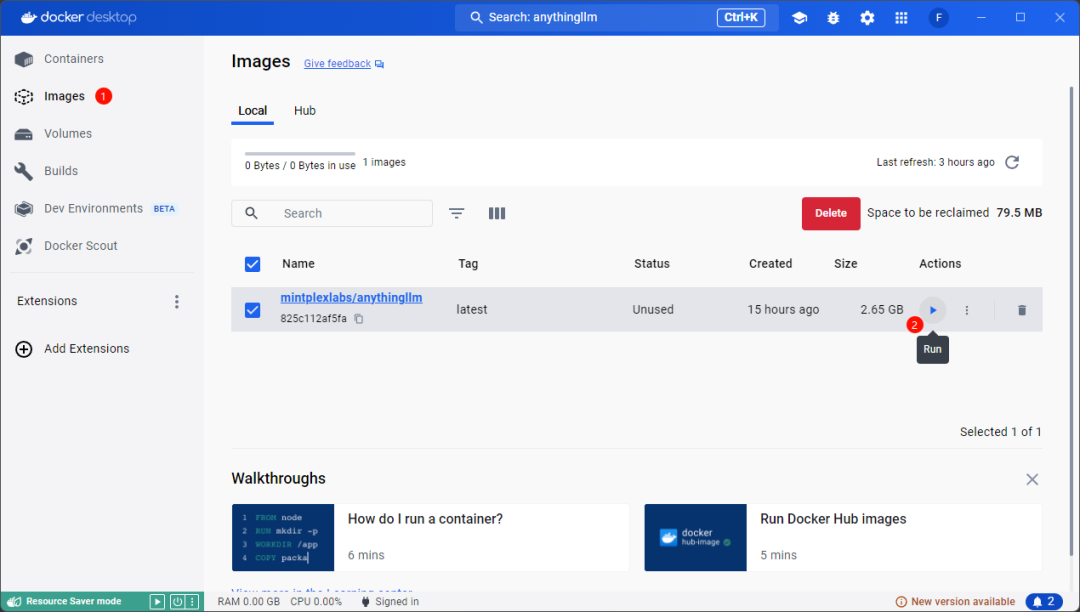
-
如下图所示,输入容器名称和端口号,这个可以随便输入,但不能和其他已有的容器名或端口号重复(如果有的话)
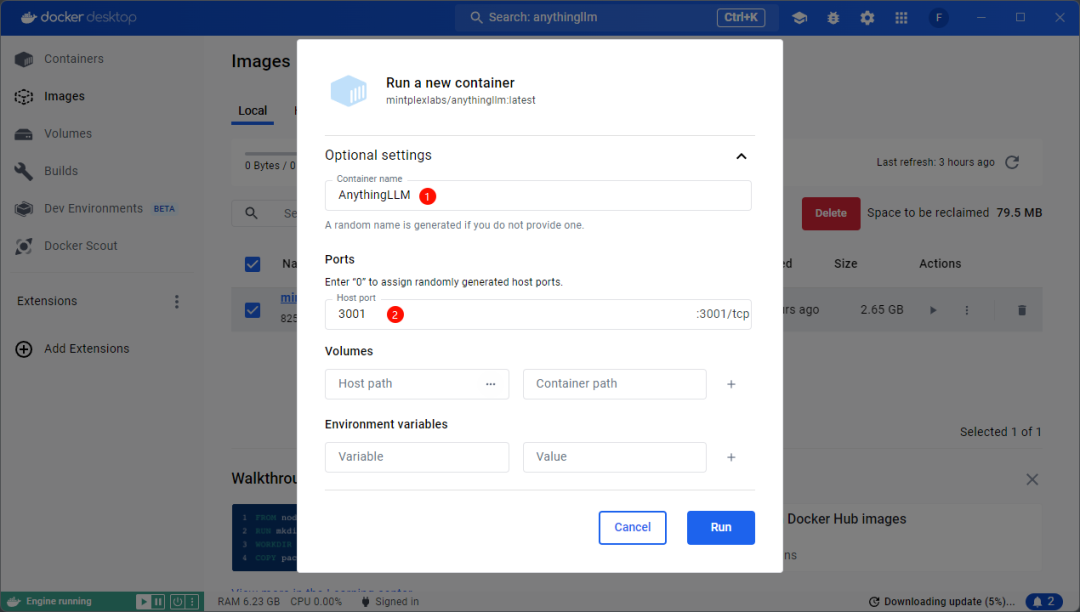
-
镜像启动后可以点击如下图所示位置的链接,或者直接在浏览器中输入 localhost:3001启动AnythingLLM
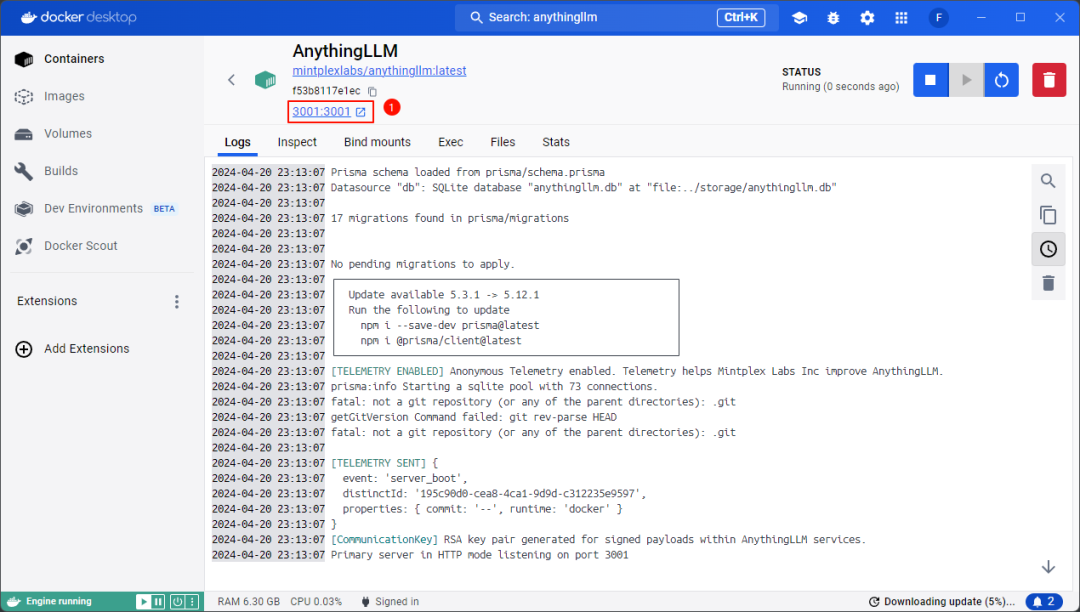
4 配置AnythingLLM
-
点击按钮 Get started 进入设置向导界面
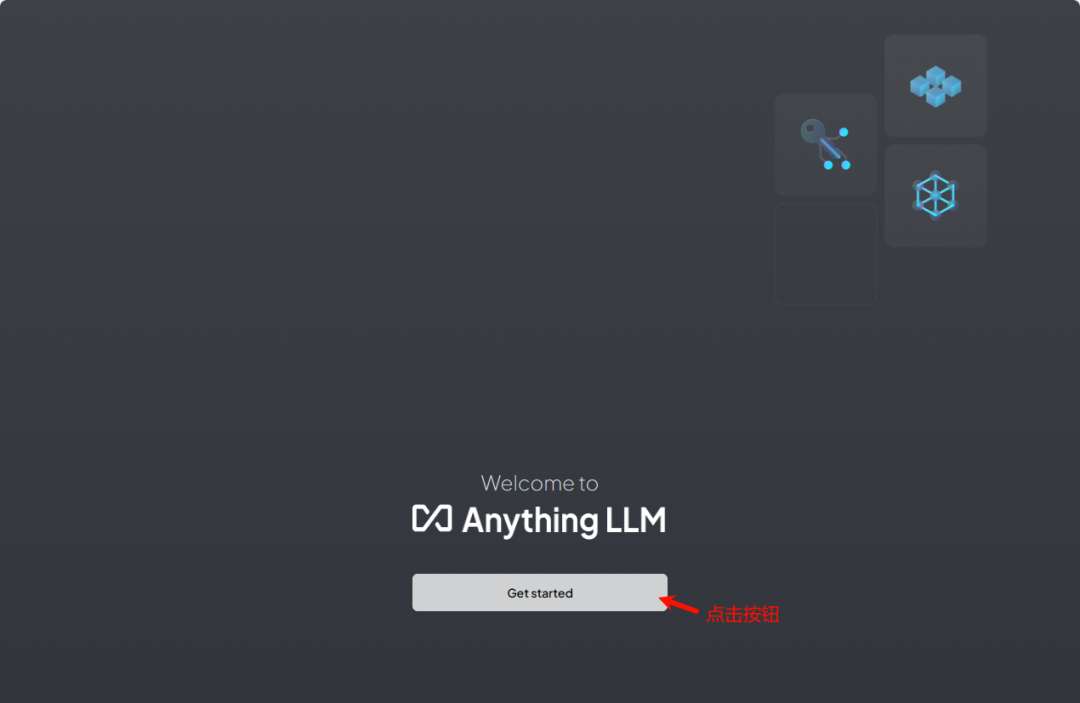
-
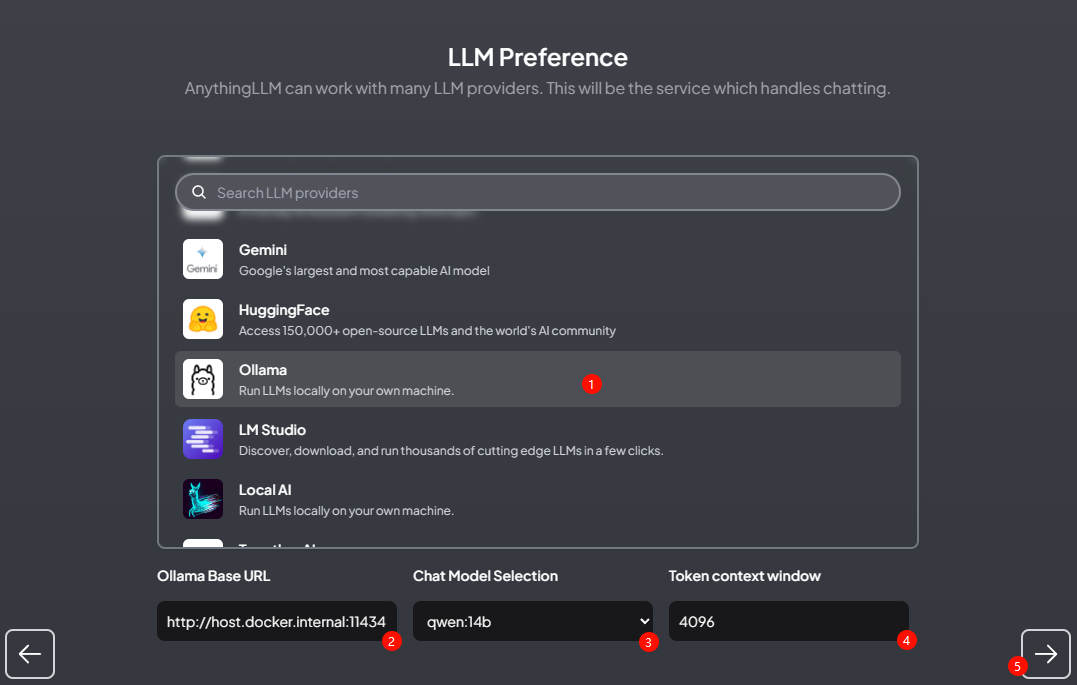
选择大模型。如下图所示设置使用 Ollama,然后设置参数 -
指定 Ollama Base URL为 http://host.docker.internal:11434 -
指定 Chat Model Selection为 qwen:14b -
指定 Token context window为 4096
注:AnythingLLM支持使用闭源模型的API。
”
-
选择默认的 AnythingLLM Embedder
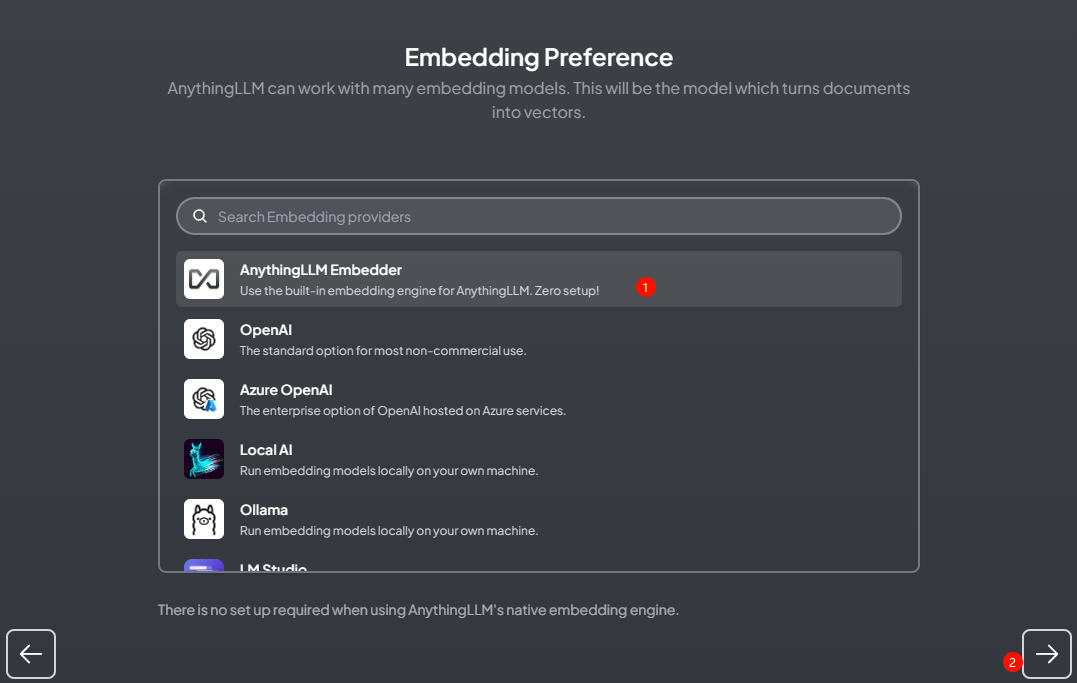
-
选择采用默认的 LanceDB作为向量数据坑
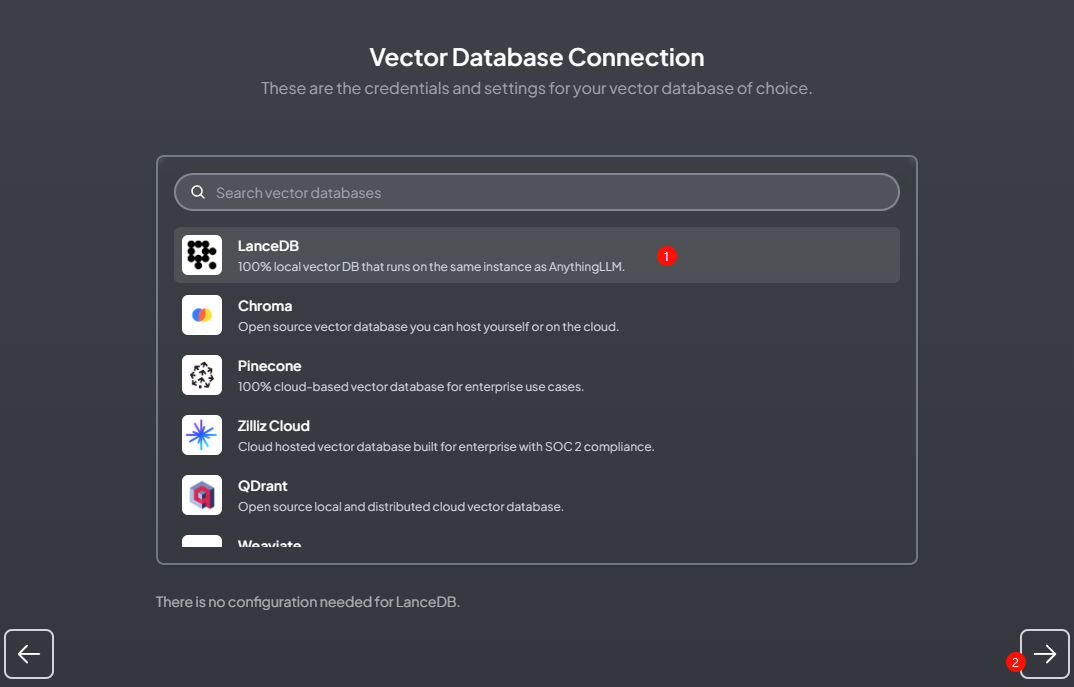
-
如下图所示设置
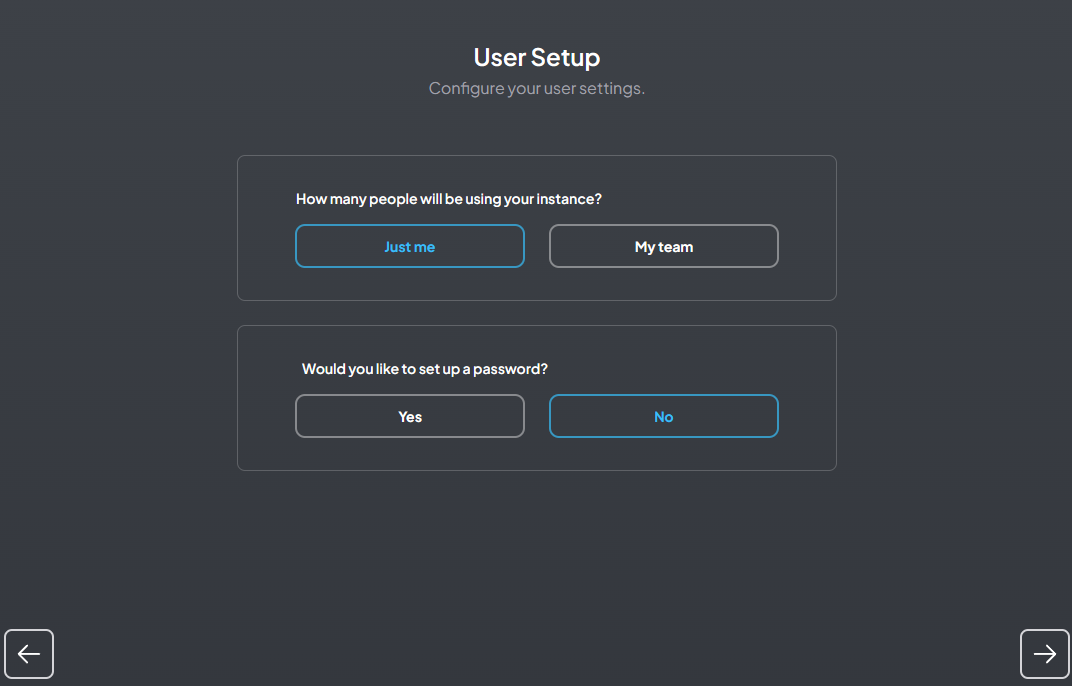
-
检查并确认前面的设置
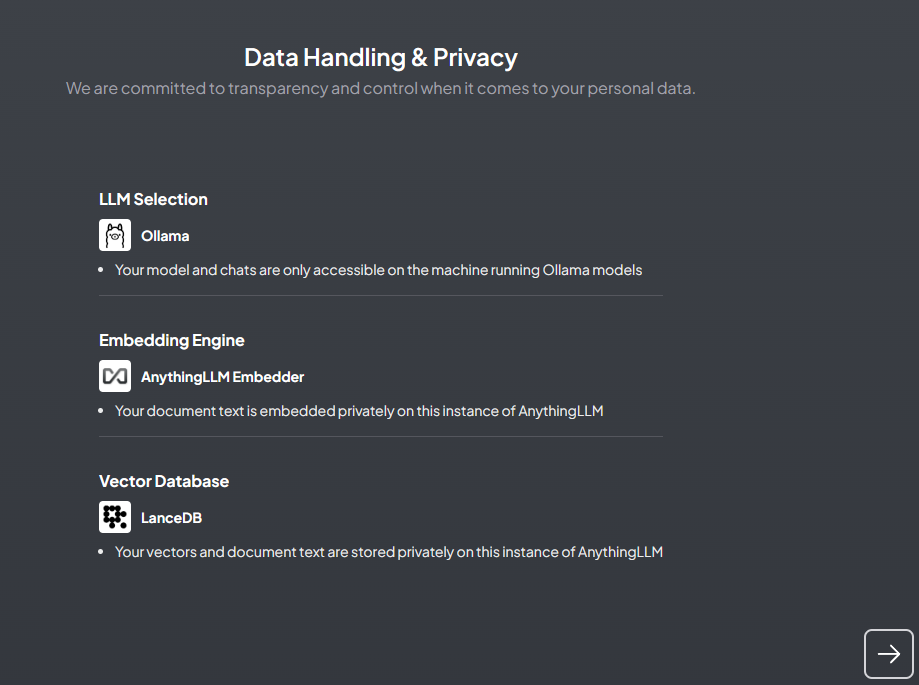
-
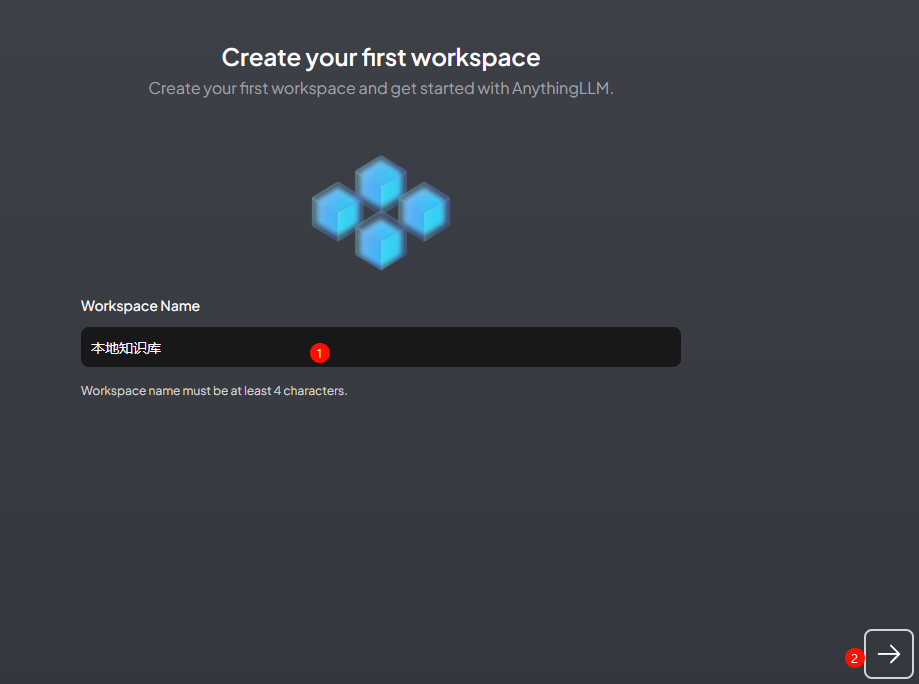
为工作空间指定名称,并进入下一步
-
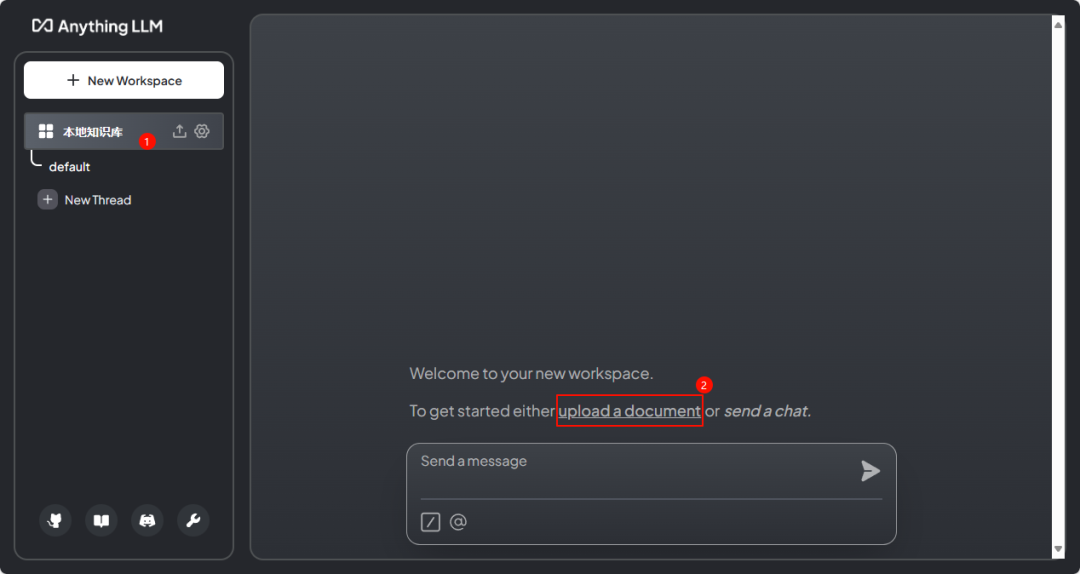
如下图所示,点击链接 upload a document打开文档上传界面
-
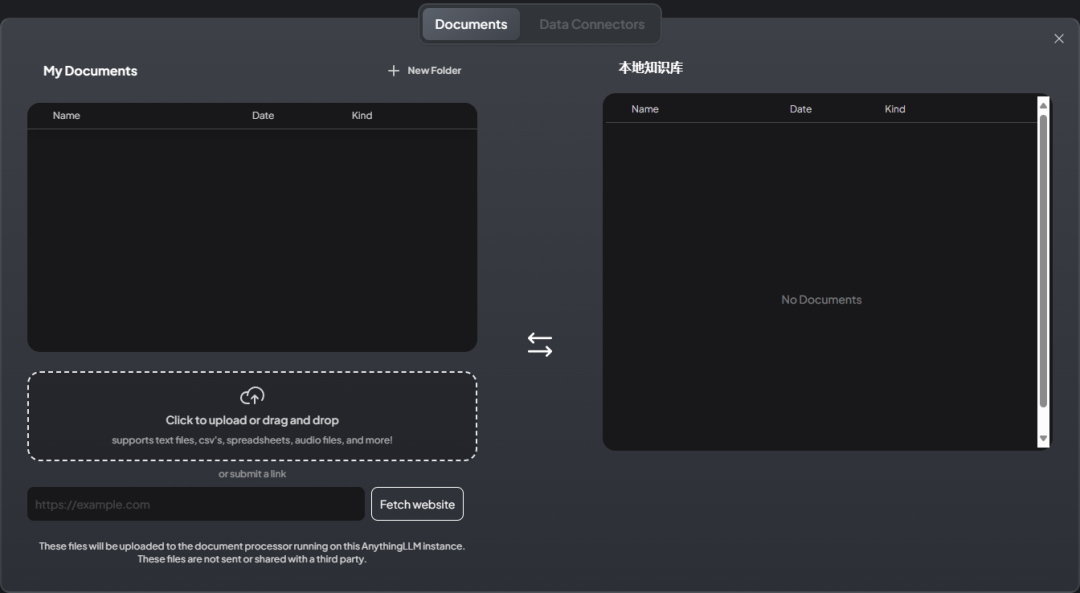
文档上传界面如图所示
-
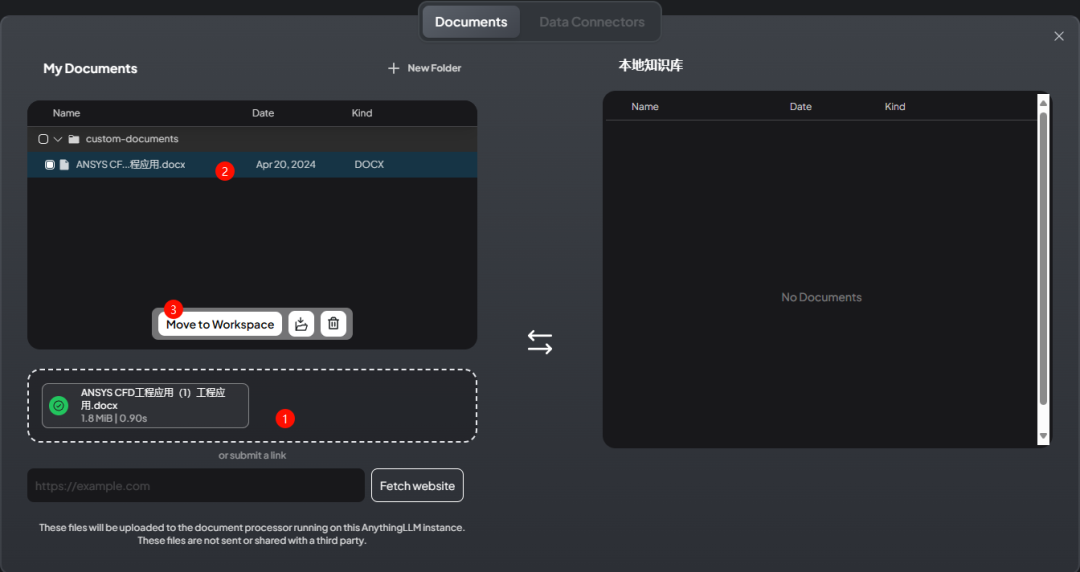
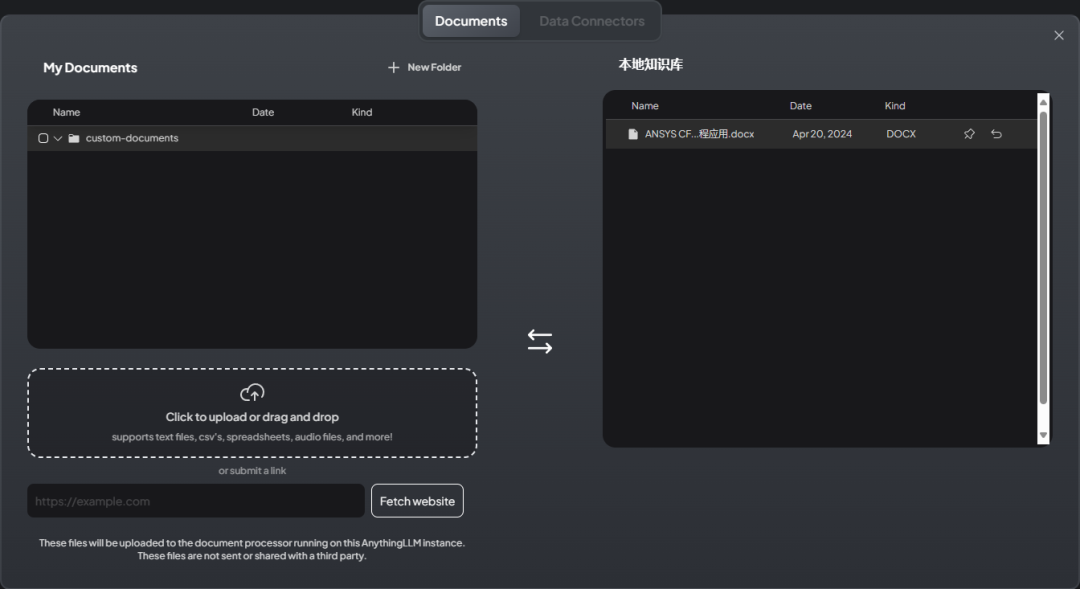
可以添加自己的文档,并将文档移入工作区
-
文档移入后如下图所示
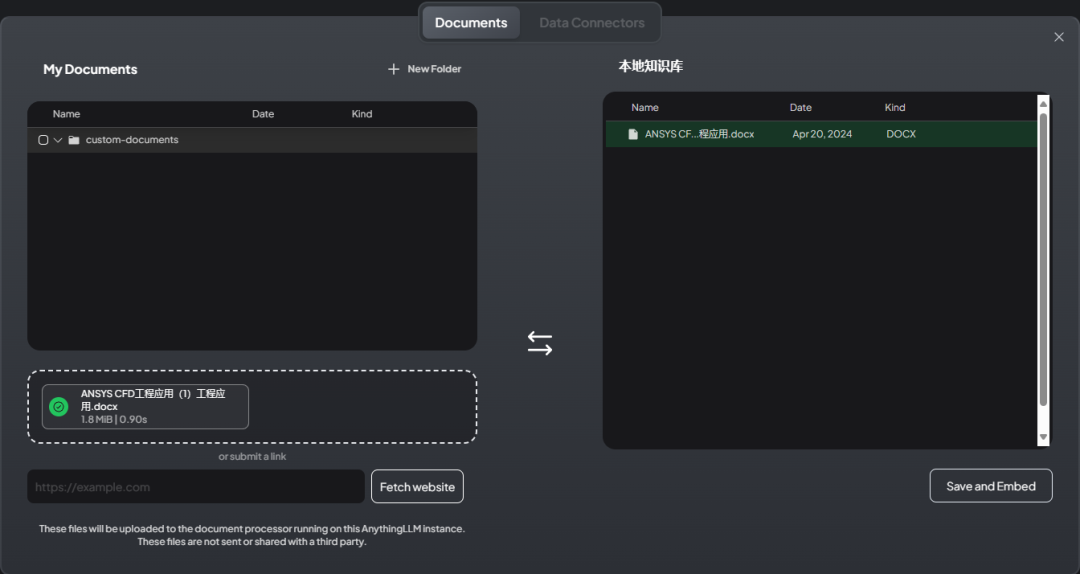
-
点击按钮 Save and Embed 处理文档
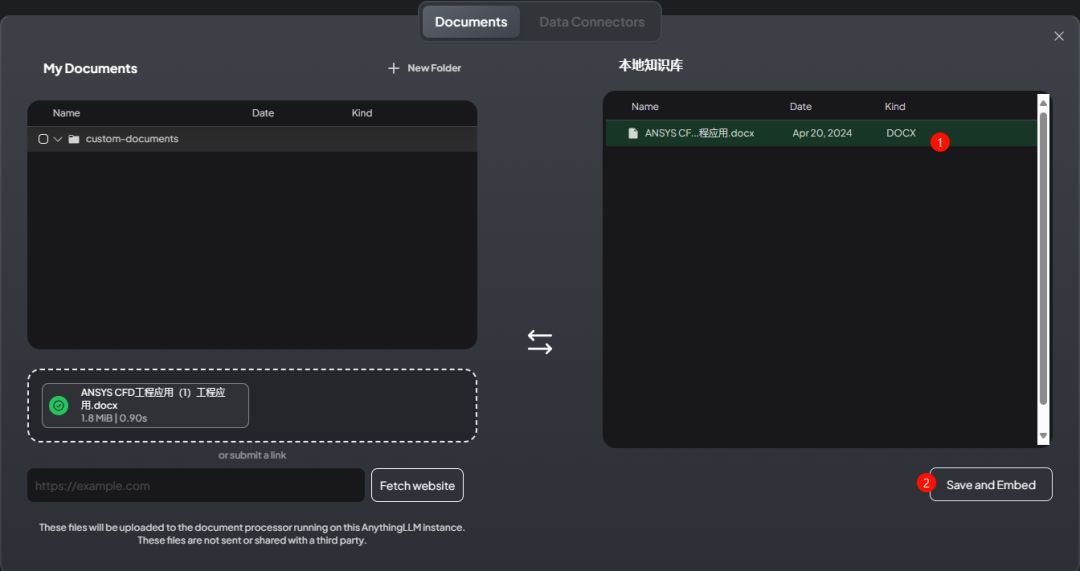
-
文档处理完毕后可以进行测试,如下图所示
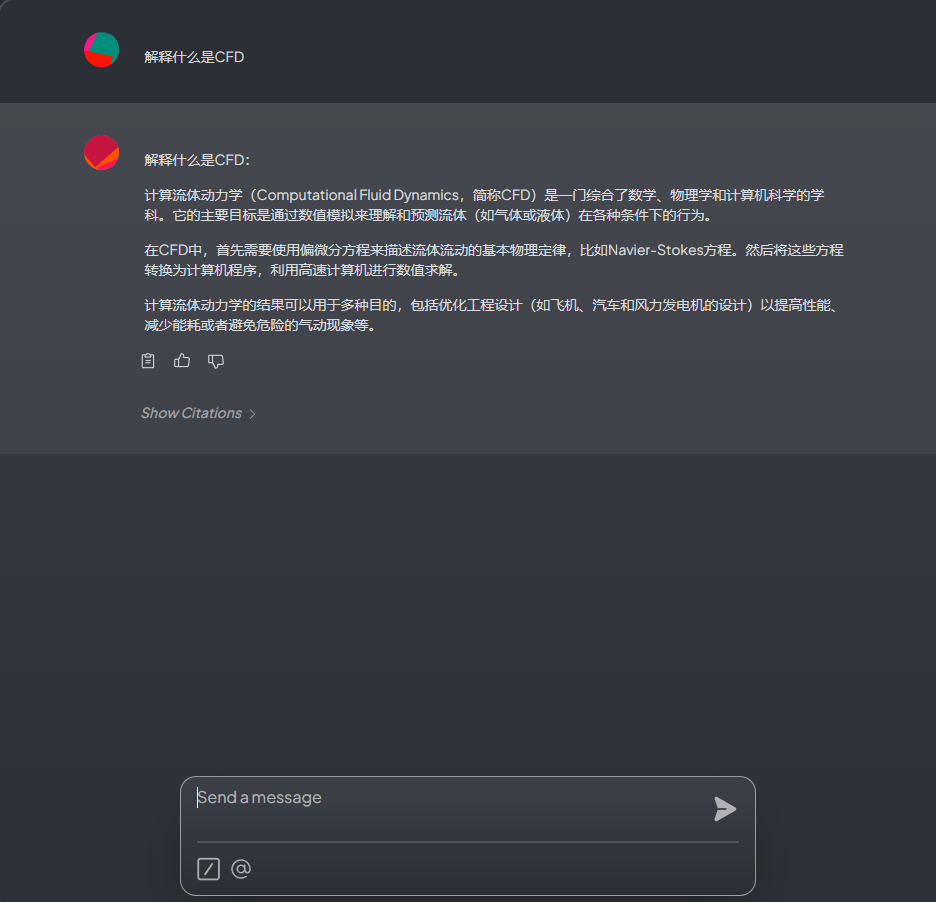
5 知识库管理
-
可以点击左下角的设置按钮打开设置面板
-
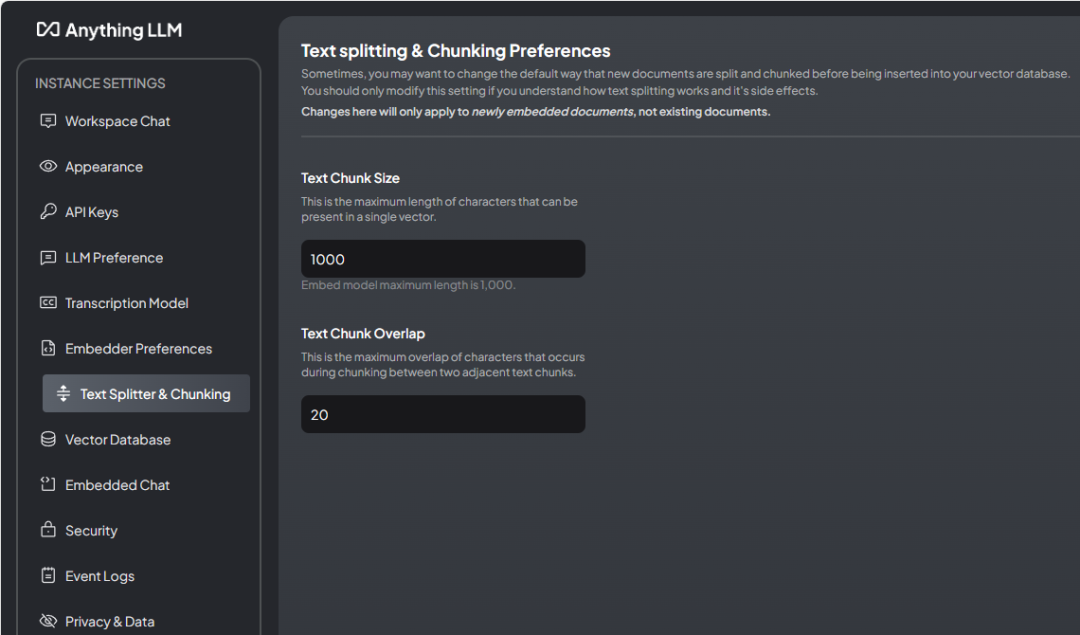
如下图所示可以设置语料分割参数
-
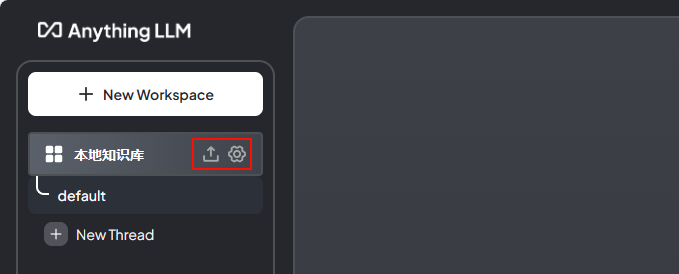
也可以点击左上角的按钮,如下图所示
-
其中第一个按钮打开的是文档管理对话框
-
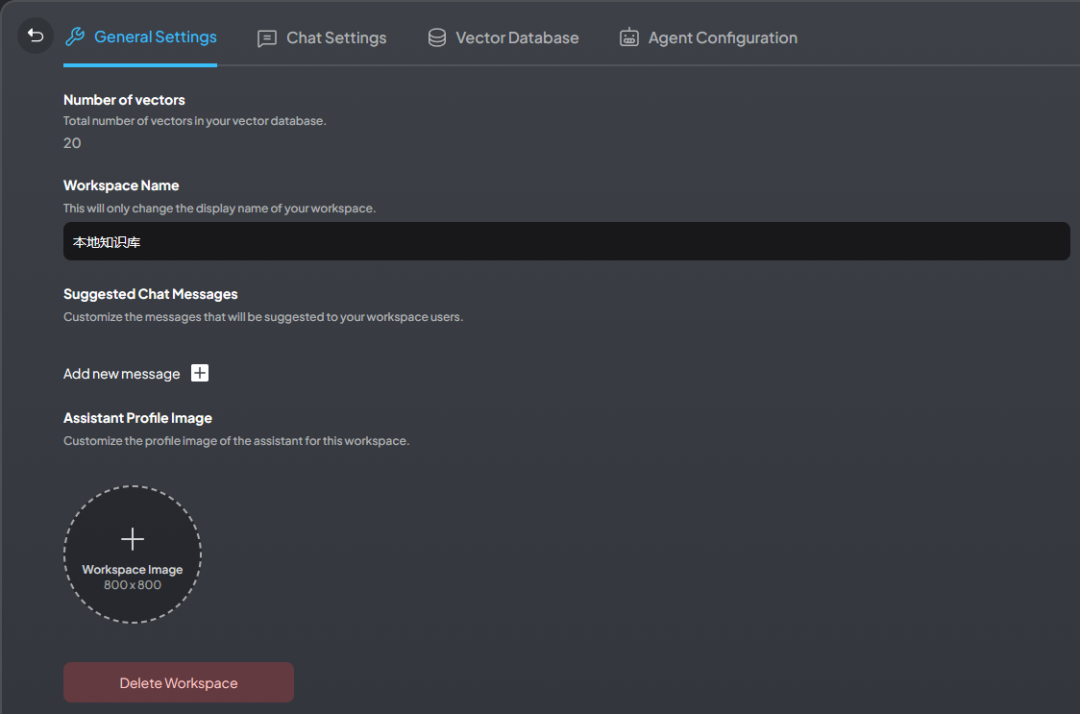
第二个按钮打开的是模型设置面板
具体设置方法可以参阅文档。提高知识库性能的一些方法包括:
-
使用更强大的底座模型。底座模型用于数据的输入和输出。使用GPT4效果肯定要比使用小规模的开源模型。AnythingLLM支持以API方式调用如GPT4、Claude3、Gemini Pro等大模型。目前似乎还没有提供国内大模型的接口。 -
使用更好的Embedding模型。目前AnythingLLM内置了一个嵌入模型。其也支持调用如OpenAI、Ollama等提供的其他嵌入模型。 -
分词参数。用于分割数据。这个参数调整需要尝试。 -
使用更高效的向量库。 -
良好的原始数据。
6 关闭Docker
当不使用大模型时,为了节省资源,可以选择关闭容器。
-
点击 Containers ,点击关闭按钮可以关闭容器
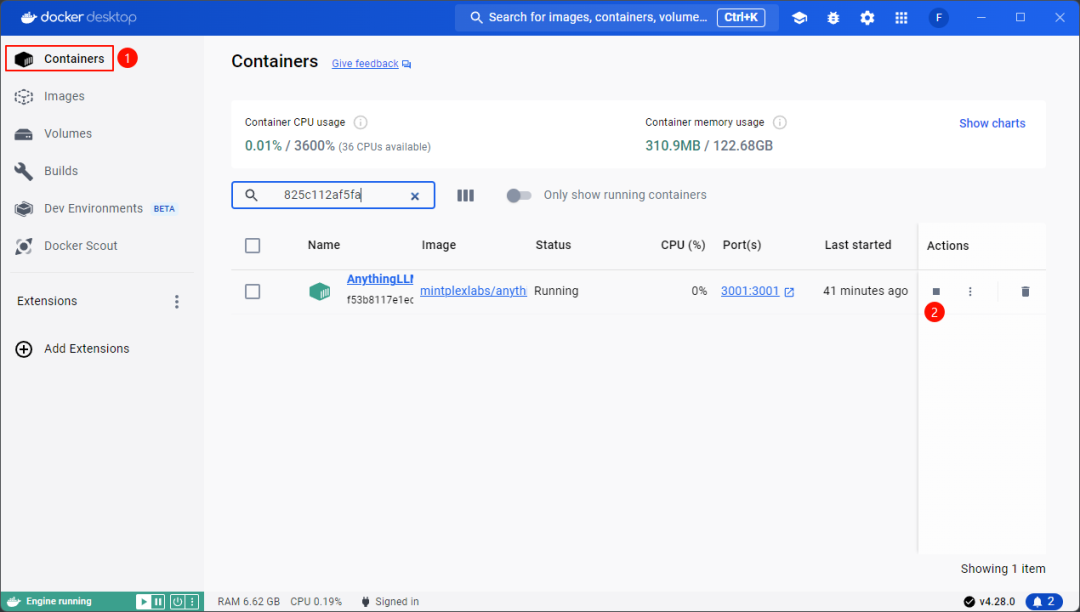
(完)
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册