
UDF简介
什么是UDF
用户自定义函数,或UDF,是用户自编的程序,它可以动态的连接到FLUENT求解器上来提高求解器性能。用户自定义函数用C语言编写。使用DEFINE宏来定义。UDF中可使用标准C语言的库函数,也可使用FLUENT提供的预定义宏,通过这些预定义宏,可以获得FLUENT求解器得到的数据。
UDF使用时可以被当作解释函数或编译函数。解释函数在运行时读入并解释。而编译UDF则在编译时被嵌入共享库中并与FLUENT连接。解释UDF用起来简单,但是有源代码和速度方面的限制不足。编译UDF执行起来较快,也没有源代码限制,但设置和使用较为麻烦。
为什么要使用UDF
一般说来,任何一种软件都不可能满足每一个人的要求,FLUENT也一样,其标准界面及功能并不能满足每个用户的需要。UDF正是为解决这种问题而来,使用它我们可以编写FLUENT代码来满足不同用户的特殊需要。当然,FLUENT的UDF并不是什么问题都可以解决的,在下面的章节中我们就会具体介绍一下FLUENT UDF的具体功能。现在先简要介绍一下UDF的一些功能:
l 定制边界条件,定义材料属性,定义表面和体积反应率,定义FLUENT输运方程中的源项,用户自定义标量输运方程(UDS)中的源项扩散率函数等等。
l 在每次迭代的基础上调节计算值
l 方案的初始化
l (需要时)UDF的异步执行
l 后处理功能的改善
l FLUENT模型的改进(例如离散项模型,多项混合物模型,离散发射辐射模型)
UDF基础
1、单元(Cells),面(Faces),区域(Zones)和线程(Threads)
单元和单元面被组合为一些区域(zones),这些区域规定了计算域(例如,入口,出口,壁面)的物理组成。当用户使用FLUENT 中的UDF 时,用户的UDF 可调用流体区域或是边界区域的计算变量。UDF需要获得适当的变量,比如说是区域参考和单元ID,以便标定各个单元。
区域(A zone)是一群单元或单元面的集合,它可以由模型和区域的物理特征(比如入口,出口,壁面,流体区域)来标定。例如,一些被指定为面域(a face zone)的单元面可以被指定为velocity-inlet 类型,由此,速度也就可指定了。线程(A thread)是FLUENT 数据结构的内部名称,可被用来指定一个区域。Thread 结构可作为数据储存器来使用,这些数据对于它所表示的单元和面来说是公用的。
打个比方来说,Thread就是公路,连接的Cell和Face,Cell和Face就相当于公路上汽车停靠的站点,Cell_t这个面向的是单元,而Face_t面向的是边或者面(二维或三维)。在FLUENT循环过程中,一般是用Thread作线程检索,而Cell或者Face作检索过程中位置参数的指示。
2、解释型interpreted和编译型compiled UDF的比较
编译型UDF和FLUENT的构建方式一样。脚本Makefile 被用来调用C编译器来构建一个当地目标代码库。目标代码库包含高级C语言源代码的机器语言翻译。代码库在FLUENT 运行时由“动态加载”过程连接到FLUENT上。连接后,与共享库的联系将会被保存在用户的case文件中。这样,当FLUENT以后再读入case文件时,此编译库将会与FLUENT 自动连接。这些库是针对计算机的体系结构和一定版本的FLUENT使用的。所以,当FLUENT更新,或计算机操作系统改变,或是在不同类型的机器上运行时,这些库必须重新构建。
编译型UDF需要安装C语言编译器,FLUENT支持的编译器类型可从安装目录下v150fluentntbinntx86中的udf.bat文件中查询。
而解释UDF则是在运行时,直接从C语言源代码编译和装载。在FLUENT运行中,源代码被编译为中介的独立于物理结构的使用C预处理程序的机器代码。当UDF 被调用时,机器代码由内部仿真器或注释器执行。注释器不具备标准C编译器的所有功能,它不支持C语言的某些原理。所以,在使用 interpreted UDF 时,有语言限制。例如,interpreted UDF 不能够通过废弃结构(dereferencing structures)来获得FLUENT 数据。要获得数据结构,必须使用由FLUENT 提供的预定义宏。还有就是是FLUENT interpreter不能识别指针数组。这些功能必须由compiled UDF 来执行。
编译后,用户的C函数名称和内容将会被储存在case文件中。函数将会在读入case文件时被自动编译。独立于物理结构的代码的外层可能会导致执行错误,但却可使UDF共享不同的物理结构,操作系统和FLUENT版本。如果运行速度较慢,UDF不用被调节就可以编译代码的形式(in compiledmode)运行。
选择interpreted UDF或是compiled UDF时,注意以下内容:
-
Interpreted UDF
o 对其它平台是便捷的(portable)。
o 可作为(compiled UDF)来运行。
o 不需C编译器。
o 比compiled UDF慢。
o 需要较多的代码。
o 在使用C语言上有限制。
o 不能与编译系统或用户库(compiled system or user libraries)连接。
o 只能使用预定义宏来获得FLUENT结构中的数据。
-
Compiled UDF
o 比interpreted UDF运行快。
o 在使用C语言上不存在限制。
o 可用任何ANSI-compliant C 编译器编译。
o 能调用以其他语言编写的函数 (specifics are system-and compiler-dependent)。
o 机器物理结构需要用户建立FLUENT (2D or 3D) 的每个版本的共享库(a shared library for eachversion of FLUENT (2D or 3D) needed for your machine architecture)。
o 如果包含有注释器(interpreter)不能处理得C语言元素,则不能作为(interpreted UDF )运行。
总的来说,当决定使用那种类型的UDF 时:
-
使用interpretedUDF作为简单的函数
-
使用compiled UDF作为复杂的函数,这些函数
o 对CPU有较大要求(例如每次运行时,在每个单元上均须调用的属性UDF(a property UDF)。
o 需要使用编译库(require access to acompiled library)。
解释式UDF的限制
解释式UDF不能包含以下C语言:
-
goto语句。
-
非ANSI-C原型语法
-
直接的数据结构查询(direct datastructure references)
-
局部结构的声明
-
联合(unions)
-
指向函数的指针(pointers tofunctions)
-
函数数组。
在访问FLUENT求解器数据的方式上解释式UDF也有限制。解释式UDF不能直接访问存储在FLUENT结构中的数据。它们只能通过使用Fluent提供的宏间接地访问这些数据。另一方面,编译式UDF没有任何C编程语言或其它注意的求解器数据结构的限制。
简单算例
1、计算模型如下图:

入口速度随高度变化
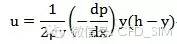
2、UDF文件编写如下:
#include "udf.h"
DEFINE_PROFILE(inlet_parab, thread, equation)
{
real x[3],y;
face_t f;
float u;
floatrho=1.0;
floatmu=0.1;
floatdp=0.3;
floath=2.0;
begin_f_loop(f,thread)
{
F_CENTROID(x, f, thread);
y =x[1];
u=dp*0.5/rho/mu*y*(y-h);
F_PROFILE(f, thread, equation) = u;
}
end_f_loop(f, thread)
}
3、导入并编译UDF
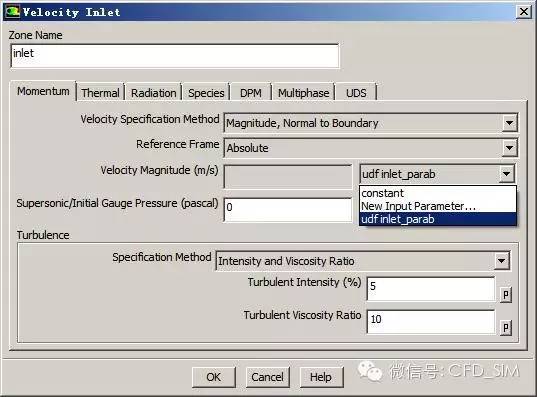
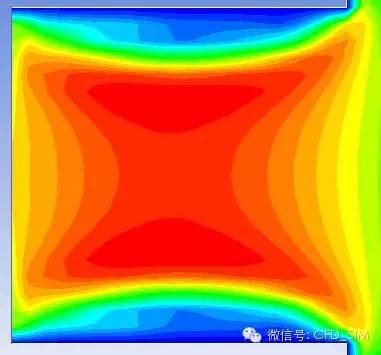
4、计算结果
C语言基础
数据类型
FLUENT的UDF解释程序支持下面的C数据类型:
-
Int:整型
-
Long:长整型
-
Real:实数
-
Float:浮点型
-
Double:双精度
-
Char:字符型
注意:UDF解释函数在单精度算法中定义real类型为float型,在双精度算法宏定义real为double型。因为解释函数自动作如此分配,所以使用在UDF中声明所有的float和double数据变量时使用real数据类型是很好的编程习惯。
常数
常数是表达式中所使用的绝对值,在C程序中用语句#define来定义。最简单的常数是十进制整数(如:0,1,2)包含小数点或者包含字母e的十进制数被看成浮点常数。按惯例,常数的声明一般都使用大写字母。
例如,你可以设定区域的ID或者定义YMIN和YMAX如下:
#defineWALL_ID 5
#define YMIN0.0
#define YMAX0.4064
变量
变量或者对象保存在可以存储数值的内存中。每一个变量都有类型、名字和值。变量在使用之前必须在C程序中声明。这样,计算机才会提前知道应该如何分配给相应变量的存储类型。
在进行变量声明时,变量名的头字母必须是C所允许的合法字符,变量名字中可以有字母,数字和下划线。需要注意的是,在C程序中,字母是区分大小写的。下面是变量声明的例子:
int n; /*声明变量n为整型*/
int i1,i2; /*声明变量i1和i2为整型*/
float tmax =0.; /* tmax为浮点型实数,初值为0 */
realaverage_temp = 0.0; /* average_temp为实数,赋初值为0.1*/
函数
函数是用来完成一定任务的一系列语句。在定义该函数的同一源代码中,这些任务可能对其它的函数有用,也可能会被用于完成源文件以外的函数中。每个函数都包括一个函数名以及函数名之后的零行或多行语句,其中有大括号括起来的函数主体可以完成所需要的任务。函数可以返回特定类型的数值。
函数有很多数据类型,如real,void等,其相应的返回值就是该数据类型,如果函数的类型是void就没有任何返回值。
数组
数组的定义格式为:名字[数组元素个数]
C语言数组的下标是从0开始的。变量的数组可以具有不同的数据类型。
下面是数组的例子:
int a[10],b[10][10];
realradii[5];
a[0] =1; /* 变量a为一个一维数组*/
radii[4] =3.14159265; /*变量radii为一个一维数组*/
b[10][10] =4; /*变量b为一个二维数组*/
指针
指针变量的数值是其它变量存储于内存中的地址值。C程序中指针变量的声明必须以*开头。指针广泛用于提取结构中存储的数据,以及在多个函数中通过数据的地址传送数据。例如:
int *ip;
本语句声明了一个指向整型变量的指针变量ip。此时你可以为指针变量分配一个地址值了。现在假定你要将某一地址分配给指针ip,你可以用取地址符&来实现。例如:
ip = &a;
就分配给指针ip变量a的地址值了。
要得到指针变量所指向的单元的值,你可以使用:
*ip
你还可以为指针ip所指向的变量赋值,例如:
*ip = 4;
将4赋给指针ip所指向的变量。下面是使用指针的例子:
int a = 1;
int *ip;
ip =&a; /* &a返回了变量a的地址值*/
printf("contentof address pointed to by ip = %dn", *ip);
*ip = 4; /* a = 4 */
printf("nowa = %dn", a);
在上面的语句中,整型变量赋初值为1。然后为整型变量声明一个指针。然后整型变量a的地址值分配给指针ip。然后用*ip来输出指针ip所指向的值(该值为1)。然后用*ip间接的给变量a赋值为4。然后输出a的新值。指针还可以指向数组的起始地址,在C中指针和数组具有紧密的联系。
控制语句
你可以使用控制语句,如if, if-else和循环来控制C程序中语句的执行顺序。控制语句决定了程序序列中下一步该执行的内容
if语句
if语句是条件控制语句的一种。格式为:
if (逻辑表达式)
{语句}
其中逻辑表达式是判断条件,语句是条件满足时所要执行的代码行。
if-else语句
if-else语句是另一种条件控制语句。格式为:
if (逻辑表达式)
{语句}
else
{语句}
如果逻辑表达式条件满足,则执行第一个语句,否则执行下面的语句。
for循环
for循环是C程序最为基本的循环控制语句。它和FORTRAN中的do循环很类似。格式为:
for (起点; 终点; 增量)
{语句}
其中起点是在循环开始时执行的表达式;终点是判断循环是否结束的逻辑表达式;增量是循环迭代一次之后执行的表达式(通常是增量计数器)。
常用的C运算符
运算符是内部的C函数,当它们对具体数值运算时会得到一个结果。常用的C运算符是算术运算符和逻辑运算符。
算术运算符
下面是一些常用的算术运算符。
= 赋值
+ 加
- 减
* 乘
/ 除
% 取模
++ 增量
-- 减量
注意:乘、除和取模运算的优先级要高于加、减运算。除法只取结果的整数部分。取模只取结果的余数部分。++运算符是增量操作的速记符。
逻辑运算符
下面是一些逻辑运算符。
< 小于
<= 小于或等于
> 大于
>= 大于或等于
== 等于
!= 不等于
C库函数
当你书写UDF代码时,你可以使用C编译器中包括的标准数学库和I/O函数库。下面各节介绍了标准C库函数。标准C库函数可以在各种头文件中找到(如:global.h)。这些文件都被包含在udf.h文件中。
三角函数
下面的三角函数都是计算变量x(只有一个还计算y)的三角函数值。函数和变量都是双精度实数变量。
|
double acos (double x); |
返回x的反余弦函数 |
|
double asin (double x); |
返回x的反正弦函数 |
|
double atan (double x); |
返回x的反正切函数 |
|
double atan2 (double x, double y); |
返回x/y的反正切函数 |
|
double cos (double x); |
返回x的余弦函数 |
|
double sin (double x); |
返回x的正弦函数 |
|
double tan (double x); |
返回x的正切函数 |
|
double cosh (double x); |
返回x的双曲余弦函数 |
|
double sinh (double x); |
返回x的双曲正弦函数 |
|
double tanh (double x); |
返回x的双曲正切函数 |
各种数学函数
下面列表中,左边是C函数,右边是对应数学函数:

标准I/O函数
C中有大量的标准输入输出(I/O)函数。在很多情况下,这些函数在指定的文件中工作。下面是一些例子。
|
FILE *fopen(char *filename, char *type); |
打开一个文件 |
|
int fclose(FILE *fd); |
关闭一个文件 |
|
int fprintf(FILE *fd, char *format, ...); |
格式化输出到一个文件 |
|
int printf(char *format, ...); |
输出到屏幕 |
|
int fscanf(FILE *fd, char *format, ...); |
格式化读入一个文件 |
函数fopen和fclose分别打开和关闭一个文件。函数fprintf以指定的格式写入文件,函数fscanf以相同的方式从某一文件中将数据读入。函数printf是一般的输出函数。fd是一个文件指针,它所指向的是包含所要打开文件的信息的C结构。除了fopen之外所有的函数都声明为整数,这是因为该函数所返回的整数会告诉我们这个文件操作命令是否成功执行。
用#define实现宏置换
UDF解释程序支持宏置换的C预处理程序命令。当你使用#define宏置换命令,C预处理程序(如,cpp)执行了一个简单的置换,并用替换文本替换宏中定义的每一个自变量。
如下面的宏置换命令:
#define RAD1.2345
预处理程序会在UDF中所有的变量RAD出现的地方将RAD替换为1.2345。在你的函数中可能会有很多涉及到变量RAD的地方,但是你只需要在宏命令中定义一次,预处理程序会在所有的代码中执行替换操作。
在下面这个例子中:
#defineAREA_RECTANGLE(X,Y) ((X)*(Y))
你的UDF中所有的AREA_RECTANGLE(X,Y)都会被替换为(X)和(Y)的乘积。
用#include实现文件包含
UDF解释程序还支持文件包含的C前处理命令。当你使用#include包含一个文件时,C前处理程序会将#include filename行替换为文件名对应的文件内容。
#include " filename "
文件名对应的文件必须在当前目录中。只有udf.h文件例外,这是因为FLUENT解算器会自动将它读入。
如下面的文件包含命令:
#include"udf.h"
会将文件udf.h包含进你的源代码中。
本篇文章来源于微信公众号: 南流坊







评论前必须登录!
注册