
本案例演示利用OpenFOAM进行并行计算的基础方法。
CFD计算自然离不开并行计算,在对大规模问题进行计算时,OpenFOAM也可以使用并行模式。然而利用并行模式进行计算时,可能需要修改一些程序代码,尤其是在需要获取全场信息时。本文以一个简单的案例演示并行程序编写时需要注意的一些问题。
1 文件准备
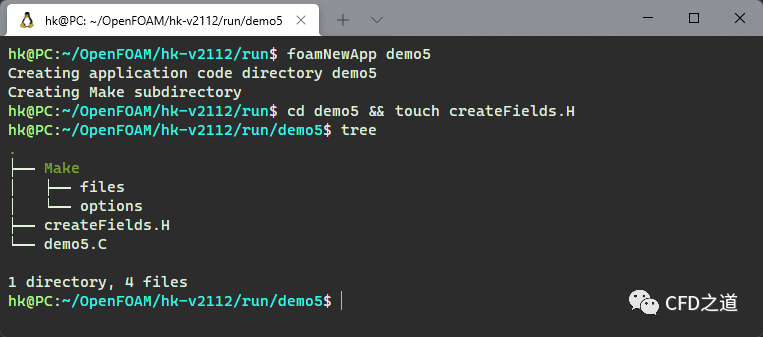
利用下面的命令准备文件:
run
foamNewApp demo5
cd demo5 && touch createFields.H
如下图所示。
2 程序代码
-
头文件 createFields.H
// 定义一些物理量
Info << "读取transportProperties文件" << endl;
IOdictionary transportProperties
(
IOobject
(
"transportProperties", //文件名
runTime.constant(), //文件路径
mesh,
IOobject::MUST_READ_IF_MODIFIED,
IOobject::NO_WRITE
)
);
// 读取物理属性nu
dimensionedScalar nu
(
"nu",
dimViscosity,
transportProperties
);
Info << "读取速度U" << endl;
volVectorField U
(
IOobject
(
"U",
runTime.timeName(),
mesh,
IOobject::MUST_READ,
IOobject::AUTO_WRITE
),
mesh
);
Info << "读取压力场p" << endl;
volScalarField p
(
IOobject
(
"p",
runTime.timeName(),
mesh,
IOobject::MUST_READ,
IOobject::AUTO_WRITE
),
mesh
);
-
源文件 demo5.C
#include "fvCFD.H"
// * * * * * * * * * * * * * * * * * * * * //
int main(int argc, char *argv[])
{
// 检查案例文件组织结构
#include "setRootCase.H"
// 创建runTime对象
#include "createTime.H"
// 创建fvMesh对象
#include "createMesh.H"
/*
对于并行运行的案例,计算域被分解成若干个processor网格。
每个子域都在单独的处理器中运行,并保存网格、U或p等对象的实例,就像串行计算一样。
Pout是每个处理器都可以写入的流,而Info只能由head进程(Processor0)使用。
在并行计算时,若想要输出计算节点的信息,需要使用Pout流
*/
Pout << "这是处理器No:" << Pstream::myProcNo() << ",网格数量:" << mesh.C().size() << endl;
// 在处理器之间交换信息,需要调用特殊的OpenMPI进程
// 计算子域的体积
scalar meshVolume;
forAll(mesh.V(), cellI)
{
meshVolume += mesh.V()[cellI];
}
Pout << "本处理器上的网格体积:" << meshVolume << endl;
// 计算所有的子域的网格体积,使用全局约简函数reduce
reduce(meshVolume, sumOp());
// 利用Info在head节点上输出信息
Info << "所有处理器上的总网格数量:" << returnReduce(mesh.C().size(), sumOp 利用命令wmake编译程序,确保没有错误或警告信息,如下图所示。
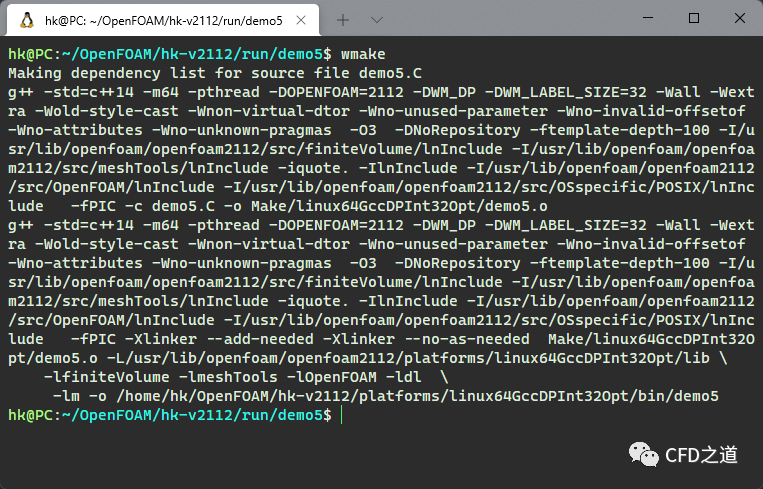
3 测试程序
这里使用cavity的案例,并行计算需要添加decomposeParDict字典。进入案例根路径,运行下面的命令添加字典文件:
foamGetDict decomposeParDict
利用decomposeParDict字典文件指定并行分区方式。这里使用的字典文件如下:
FoamFile
{
version 2.0;
format ascii;
class dictionary;
location "system";
object decomposeParDict;
}
// * * * * * * * * * * * * * * * * * //
numberOfSubdomains 4;
method hierarchical;
hierarchicalCoeffs
{
n (4 1 1);
delta 0.0001;
order xyz;
}
进入案例根路径,运行下面的命令运行案例:
blockMesh
decomposePar
mpirun -np 4 demo5 -parallel
运行结果如下图所示,可以看到并行模式获取了正确的信息。
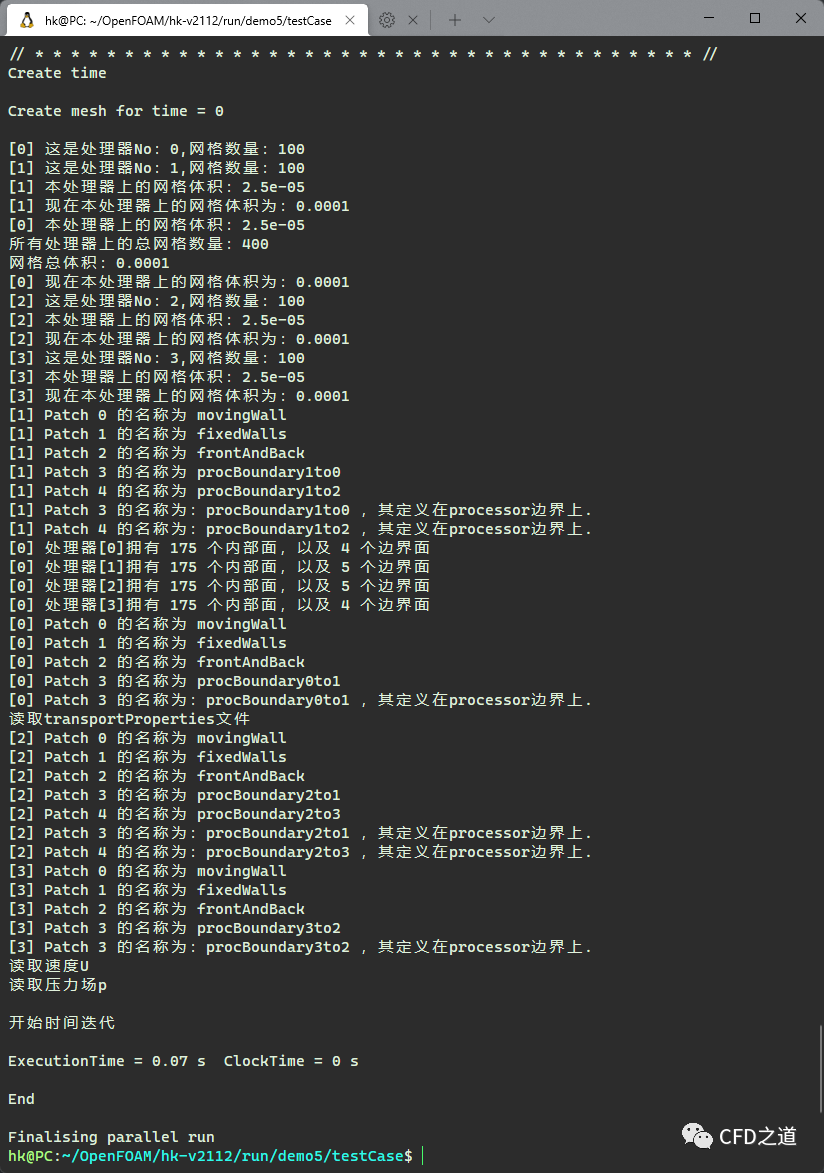
(完毕)
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册