
本文介绍在谷歌colab上训练yolov5进行目标检测的基本流程。yolo系列模型是当前最先进的目标检测模型之一。YOLO V5性能与YOLO V4不相伯仲,但其个头比V4小得多,模型训练速度也要快上不少。
本文前置条件:为了能够访问Colab,需要电脑能够科学上网。
”
Colab是谷歌提供的在线jupyter笔记本,其为劳苦大众提供了6个小时连续白嫖Tesla GPU的机会(一次使用不超过6个小时,到点儿了会自动断开连接)。另外Colab提供了多种深度学习框架支持(TensorFlow,PyTorch等),这对于学习者来讲是非常不错的计算资源。
Colab网址:https://colab.research.google.com/notebooks/welcome.ipynb
1 设置计算环境
进入Colab后第一步是新建一个笔记本,如下图所示。
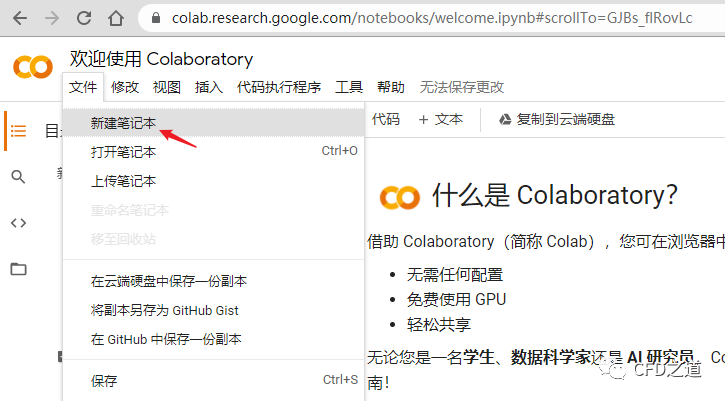
-
选择代码执行程序 → 更改运行时类型
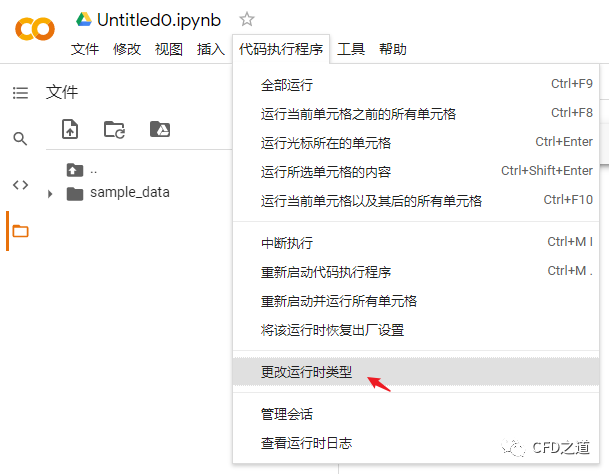
-
打开的对话框中选择硬件加速器为GPU

这样就可以使用谷歌提供的GPU了。
2 连接谷歌硬盘
Colab不会保存数据,这时候最好连接自己的谷歌硬盘。
在笔记本中输入下面的代码并运行。
# 设置工作路径为谷歌硬盘
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir("/content/drive/MyDrive/Colab Notebooks")
-
运行时会出现下面的提示信息,此时点击蓝色的链接登录到谷歌硬盘
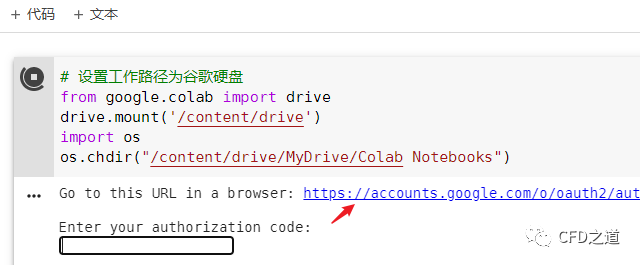
-
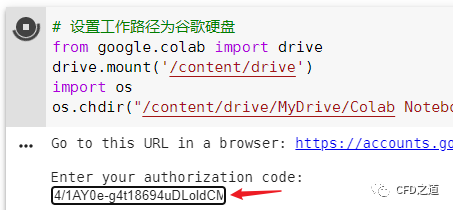
出现下面的的授权码,点击按钮拷贝授权码
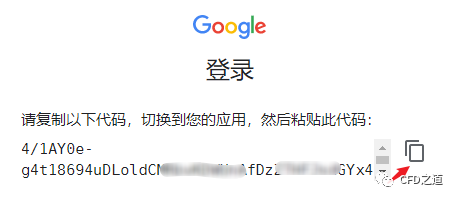
-
将授权码拷贝到下面的输入框中,并点击键盘回车键
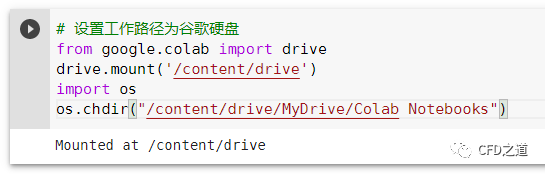
谷歌硬盘连接成功后如下图所示。
3 下载yolov5
创建新的代码块,在代码块中输入下面的代码并执行。
# 从github上下载yolov5并解压
!git clone https://github.com/ultralytics/yolov5
%cd yolov5
# 安装项目依赖
%pip install -qr requirements.txt
import torch
from IPython.display import Image, clear_output
clear_output()
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
运行完毕后如下图所示。
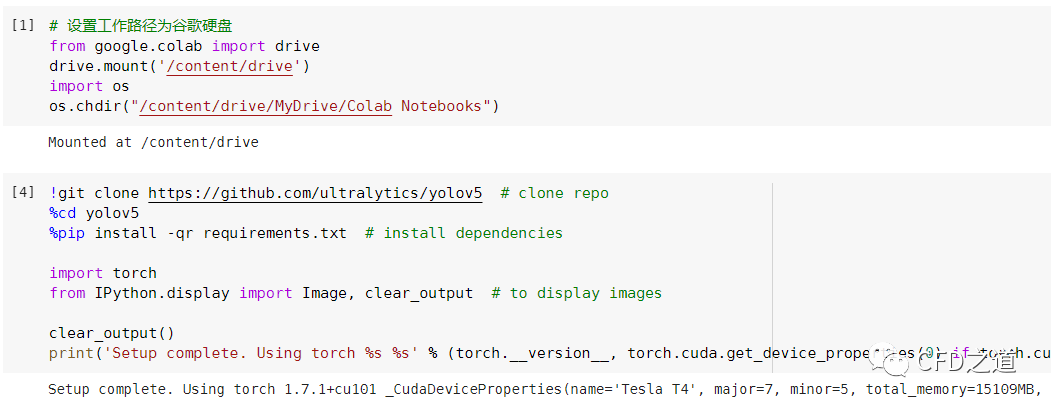
可以看到此时Colab给分配了一个Tesla T4的显卡,显存16G。pytorch版本为1.7.1,cuda版本为10.1。
注:Colab的显卡分配是随机的,有时候分配K80,有时候分配T4,全看个人运气。
”
4 上传数据集
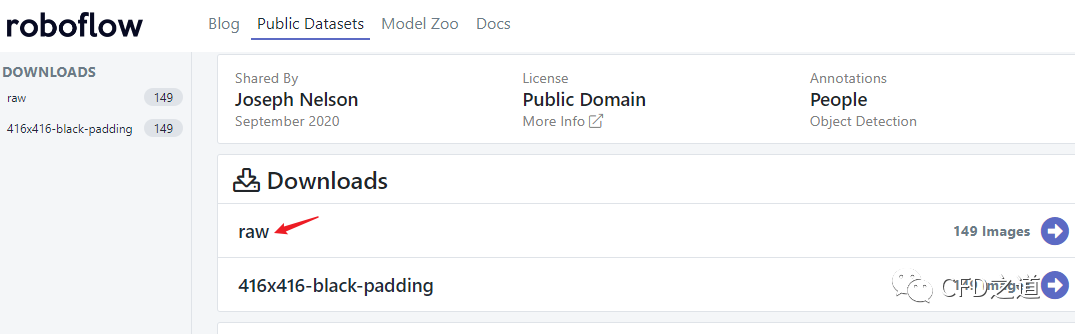
数据集可以自己制作,也可以使用别人制作的。自己制作数据集的话可以使用labelimg,注意选择输出为yolo格式。这里简单起见使用网上公开的数据集。网站(https://public.roboflow.com/)提供了很多用于目标检测的公开数据集,如常见的微软COCO数据集,牛津Pets数据集等。这里找个小型的口罩数据集,这个数据集规模很小,只有149张照片。(呃,相对于COCO十几万张照片来说真的可以忽略不计了)

-
选择YOLO v5 PyTorch格式,如下图所示
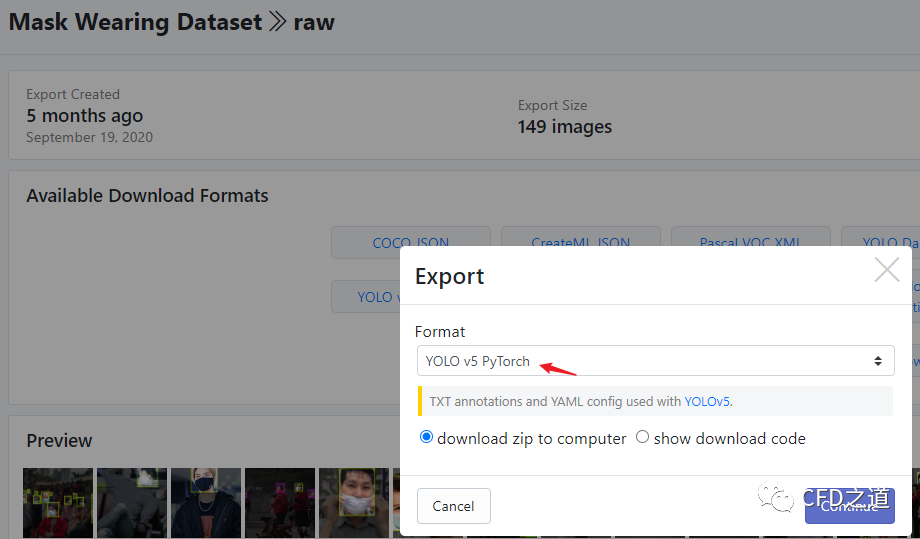
-
下载完毕后将压缩文件上传到谷歌网盘,我这里将压缩文件改名为mask.zip,如下图所示
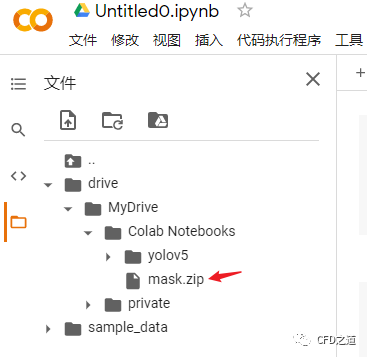
-
添加代码块,输入并运行下面的命令,将mask.zip文件解压到mask文件夹中
%cd /content/drive/MyDrive/Colab Notebooks
! mkdir ./mask/
! mv mask.zip ./mask/
%cd ./mask/
! unzip mask.zip
%cd ../yolov5/
解压完毕后目录结构如下图所示。
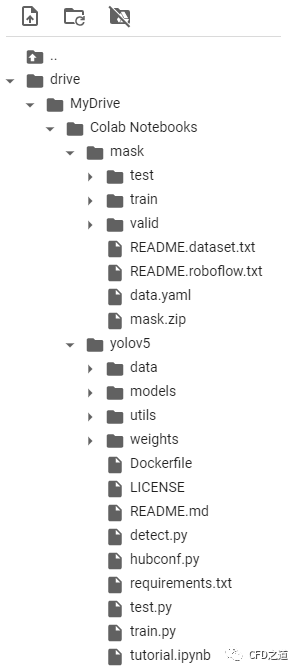
5 模型训练
在进行训练之前,需要修改一些参数。
-
修改 mask/data.yaml文件内容。主要是修改train及val的文件路径,这个根据yolov5的相对路径进行修改
(base) xugaoxiang@1070Ti:~/Works/github/mask$ cat data.yaml
train: ../mask/train/images
val: ../mask/valid/images
nc: 2
names: ['mask', 'no-mask']
-
修改文件 yolov5/models/yolov5s.yaml,将nc = 80修改为nc = 2,因为数据集中只有mask和no-mask2个类别,这里需要与数据集类别数保持一致
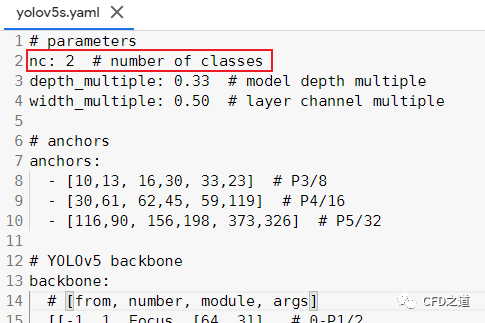
-
添加并运行代码块进行训练
!python train.py --img 640 --batch 16 --epochs 300 --data ../mask/data.yaml --cfg models/yolov5s.yaml --weights ''
输出如下图所示表示没有问题,能够正常训练。
数据集较小,训练速度勉强可以接受。
训练完毕后出现如下图所示提示。
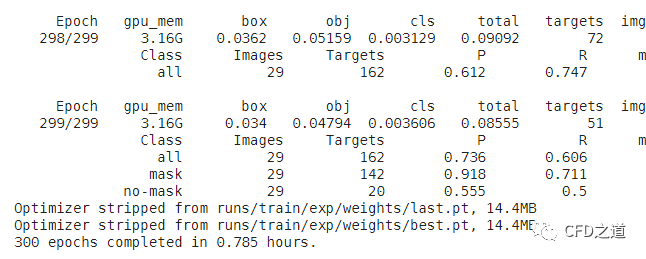
训练得到的权重文件存放在runs/train/exp/weights/文件夹中,通常情况下使用best.pt文件。
6 测试模型
去网上随便找张有带口罩的图片。比如在百度图片中找到了下面这张(这里是随便找的)。

将图片上传到Colab中,重新命名为mask.jpg(什么名字都可以,这里只是方便后面描述),将文件放到yolov5文件夹中。
添加并运行下面的代码。
! python detect.py --weight runs/train/exp/weights/best.pt --source mask.jpeg
输出结果如下图所示。结果提示识别到了7个戴口罩,2个未戴口罩。

识别后的结果存放在文件夹run/detect/exp中。打开该文件夹中的mask.jpeg文件,识别结果如下图所示,可以看到识别效果还是很不错的。只是这里人头太密集导致标签都堆起来了。

yolov5不仅提供了对静态图片的目标检测,还可以对视频文件、网络视频等进行实时检测。调用格式如下图所示。

如下所示为采用上面训练的模型对视频中的人是否戴口罩进行实时检测。
可以看到还是存在一些漏检,尤其是最后的默克尔,那么明显地未戴口罩却没有被检测出来,简直不可饶恕。
本文演示使用的是利用yolov5s进行的训练,yolo5s是yolov5系列中最小的网络模型。如果想要提高检测精度,一方面可以使用用更复杂的模型(如yolov5m、yolov5l、yolov5x等)进行训练,另一方面可以提高样本数据质量以及增加训练集样本数量(这里训练集只有149张图片)。
目标检测在工业领域应用颇多,如无人驾驶、视觉导航、危险探测等,有兴趣可以自行搜索。
说在后面:CFD耍腻了,来点新玩意儿调剂一下也不错。前阵子我说目前CFD钱途不太光明,然后就有人说我滑头,一面靠着CFD恰饭,一面还说着CFD的坏话。我就想问一句了,这年头除了挣钱恰饭之外,还能不能有点不挣钱的爱好?
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册