
本文简单描述Julia中的数组操作。
1 数组操作
在计算量集中的程序中,使用numpy内置的函数操作能够有效地提高计算性能。下面来举一个例子,考虑到CFD中经常会遇到如下的迭代式:
假设给定初始值,可以通过迭代计算得到的值。
采用迭代方法的代码可写成以下形式。
u = [0,1,2,3,4,5]
for i in 2,length(u)
print(u[i] - u[i-1],"n")
end
输出结果为:
1
1
1
1
1
其实可以改用numpy内置数组操作来实现,代码写成以下形式。
u = [0,1,2,3,4,5]
print(u[2:end] - u[1:end-1])
输出结果为:
[1 1 1 1 1]
两者结果一致。
这里看看u[2:end]与u[1:end-1]到底是多少。
u = [0,1,2,3,4,5]
print(u[2:end])
print(u[1:end-1])
输出结果为:
[1 2 3 4 5]
[0 1 2 3 4]
可以看到u[2:end]取的是第2个元素到最后一个元素的值,而u[1:end-1]取得的是第1个元素到倒数第2个元素的值。两者相减可以实现前面的。
这样做有什么用呢?对于大量密集计算来讲,这样做能节省大量的计算时间,下面来用一个复杂案例进行测试。
2 测试案例
测试案例采用二维线性对流问题,其控制方程为:
这里时间项采用向前差分,空间项采用向后差分,离散方程可写成以下格式:
式中,i为x方向角标,j为y方向角标,n为时间项角标。
可得待求项:
采用初始条件:
边界条件:
不说二话,直接上代码。
using Dates
using Printf
nx = 121;
ny = 121;
nt = 100;
c = 1;
dx = 2 / (nx - 1);
dy = 2 / (ny - 1);
sigma = 0.2;
dt = sigma * dx;
x = range(0, 2, length=nx);
y = range(0, 2, length=ny);
u = ones((ny, nx))
##指定初始条件
u[Base.floor(Int, .5 / dy):Base.floor(Int, 1 / dy + 1),Base.floor(Int, .5 / dx):Base.floor(Int, 1 / dx + 1)] .= 2;
# 循环方式进行计算
function calc()
for n in 1:nt ##loop across number of time steps
un = copy(u);
row, col = size(u);
for j in 2:row - 1
for i in 2:col - 1
u[j,i] = un[j, i] - (c * dt / dx * (un[j,i] - un[j,i - 1])) - (c * dt / dy * (un[j,i] - un[j - 1,i]))
u[1,:] .= 1
u[end,:] .= 1
u[:,1] .= 1
u[:,end] .= 1
end
end
end
end
# 测试计算消耗的时间
startTime = time()
calc()
endTime = time()
print(@sprintf("total time is :%.5fs",endTime - startTime))
计算结果如图所示。
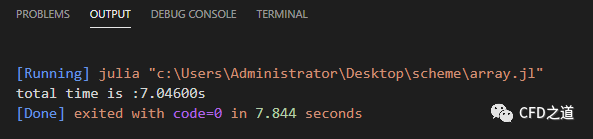
这里采用循环计算,共循环迭代了次,计算花费时间约7.046 s(不同计算机上这个时间由差别)。
下面改用向量计算方式进行迭代计算,代码改造为:
# 矩阵方式进行计算
function Matrixcalc()
for n in 1:nt ##loop across number of time steps
un = copy(u);
row, col = size(u);
u[2:end,2:end] = un[2:end,2:end] - (c * dt / dx * (un[2:end,2:end] - un[2:end, 1:end - 1])) - (c * dt / dy * (un[2:end,2:end] - un[1:end - 1,2:end]))
u[1,:] .= 1
u[end,:] .= 1
u[:,1] .= 1
u[:,end] .= 1
end
end
计算消耗的时间如下图所示。
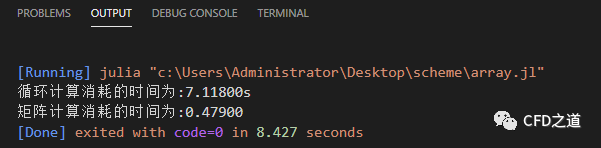
采用矩阵向量计算的方式速度比循环方式提高了15倍,这速度提升是真没话说,当然代价是代码的可读性下降了很多。
忽然发现自己年龄又增长了一岁,这他娘的杀猪刀!
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册