
除了访问网格数据的遍历宏外,并行UDF中还需要考虑计算节点之间的数据通讯,这一般采用数据交换宏来实现。
本文内容来自Fluent UDF手册
1 网格单元及网格面分区ID宏
通常网格单元及网格面都有一个分区ID,其编号从0~n-1,这里n为计算节点的数量。网格单元及网格面的分区ID分别存储在宏C_PART及F_PART中。
宏C_PART(c,tc) 存储整型的网格单元ID,宏F_PART(c,tc) 存储网格面的整型分区ID。
注意,myid可以与分区ID一起使用,因为外部网格单元的分区ID等同于相邻计算节点的ID。
1.1 网格单元分区ID
对于内部网格单元,其分区ID与计算节点ID相同。对于外部网格单元,其计算节点ID与分区ID不同。例如,在有两个计算节点(0和1)的并行系统中,计算节点node-0的外部单元的分区ID为1,计算节点node-1的外部单元的分区ID为0。
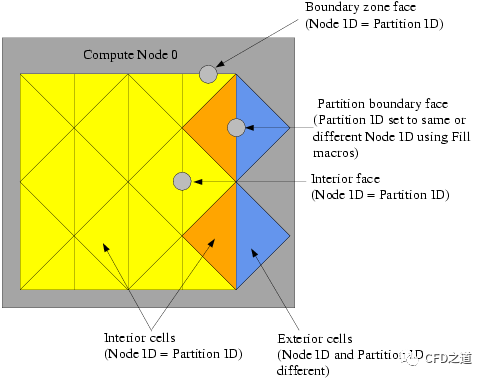
1.2 网格面分区ID
内部网格面(Interior Face)与边界面(Boundary zone face)的分区ID与计算节点ID相同。分区边界面(partition boundary face)的分区ID可以与计算节点的ID相同,也可以与相邻计算节点ID相同,这取决于宏F_PART的值。
一个计算节点的外部单元只有分区边界面,其他的网格面属于相邻的计算节点。因此,根据想要处理UDF的计算节点,可能希望将分区边界的分区作为计算节点(使用Fill_Face_Part_With_Same)或使用不同的ID(使用Fill_Face_Part_With_Different)来填充分区边界面。在使用F_PART宏访问分区ID之前,需要先填充它们。在并行udf中很少需要网格面的分区ID。
2 消息显示宏
通过使用编译器指令(例如#if RP_NODE),可以使用Message在Host或Node节点上显示消息。
示例:
#if RP_NODE
Message("Total Area Before Summing %fn",total_area);
#endif
在本例中,消息将由Node节点发送。(host不会发送。)
Message0是一种特殊形式。Message0只在node-0节点发送消息,在其他计算节点上被忽略,且不需要使用编译器指令。
Message0("Total volume = %fn",total_volume)
3 消息传递宏
当想要将数据从Host发送到所有的node时,可以使用宏host_to_node宏;当想要从node-0发送数据给host时,可以使用node_to_host宏,这两个宏称之为高级宏(High-lever Macro)。如果想要在计算节点之间传递数据,或者将所有计算节点的数据发送给node-0节点时,无法使用这些高级宏,此时需要利用其它的宏来实现。
需要注意,高级通讯宏被展开为执行许多低级消息传递操作的函数,这些操作将数据作为单个数组从一个处理器发送到其他的处理器,通过宏名称的字符标识SEND及RECV可以方便识别这些低级消息传递宏。用于向处理器发送数据的宏具有前缀PRF_CSEND,而用于从其他处理器接收数据的宏具有前缀PRF_CRECV。被发送或接收的数据类型包括:字符型(CHAR)、整数型(INT)、实数型(REAL)及逻辑型(BOOLEAN)。
逻辑布尔变量为TRUE或FALSE,实数型在单精度Fluent版本中为float,双精度版本中为double。消息传递宏在prf.h头文件中定义,包含以下类型:
PRF_CSEND_CHAR(to, buffer, nelem, tag)
PRF_CRECV_CHAR (from, buffer, nelem, tag)
PRF_CSEND_INT(to, buffer, nelem, tag)
PRF_CRECV_INT(from, buffer, nelem, tag)
PRF_CSEND_REAL(to, buffer, nelem, tag)
PRF_CRECV_REAL(from, buffer, nelem, tag)
PRF_CSEND_BOOLEAN(to, buffer, nelem, tag)
PRF_CRECV_BOOLEAN(from, buffer, nelem, tag)
这些消息传递宏都包含4个参数.
对于消息发送宏,参数说明包括:
-
to:数据被发送的目的节点ID -
buffer:被发送的数组名 -
nelem:数组元素数目 -
tag:用户自定义消息标识,约定在发送消息时使用myid
对于消息接收宏,其参数说明:
-
from:消息来源节点ID -
buffer:接收的数组名 -
nelem:数组元素的数目 -
tag:发送数据的节点ID,按惯例其与from参数相同
注意,如果要发送或接收的变量在函数中定义为real变量,那么可以使用带有_REAL后缀的宏传递消息。之后编译器再双精度版本中将宏替换为PRF_CSEND_DOUBLE或PRF_CRECV_DOUBLE,在单精度版本中将其替换为PRF_CSEND_FLOAT或PRF_CRECV_FLOAT。
因为消息传递宏是低级宏,所以需要确保在从节点处理器发送消息时,相应的接收宏出现在接收节点处理器中。注意,UDF不能直接使用消息传递宏从计算节点(0以外)发送消息到host节点。它们可以通过计算节点node-0间接地向主机发送消息。例如,如果希望并行UDF将所有计算节点的数据发送到host节点进行后处理,则必须首先将数据从每个计算节点传递到node-0节点,然后从node-0节点传递到host节点。在计算节点向node-0发送消息时,node-0节点必须有一个循环来接收来自N个节点的N条消息。
下面是一个编译型的并行UDF示例,它利用消息传递宏PRF_CSEND和PRF_CRECV。中的注释(*/)。
#include "udf.h"
#define WALLID 3
DEFINE_ON_DEMAND(face_p_list)
{
#if !RP_HOST /* Host will do nothing in this udf. */
face_t f;
Thread *tf;
Domain *domain;
real *p_array;
real x[ND_ND], (*x_array)[ND_ND];
int n_faces, i, j;
domain=Get_Domain(1); /* Each Node will be able to access its part of the domain */
tf=Lookup_Thread(domain, WALLID); /* Get the thread from the domain */
/* The number of faces of the thread on nodes 1,2... needs to be sent
to compute node-0 so it knows the size of the arrays to receive
from each */
n_faces=THREAD_N_ELEMENTS_INT(tf);
/* No need to check for Principal Faces as this UDF
will be used for boundary zones only */
if(! I_AM_NODE_ZERO_P) /* Nodes 1,2... send the number of faces */
{
PRF_CSEND_INT(node_zero, &n_faces, 1, myid);
}
/* Allocating memory for arrays on each node */
p_array=(real *)malloc(n_faces*sizeof(real));
x_array=(real (*)[ND_ND])malloc(ND_ND*n_faces*sizeof(real));
begin_f_loop(f, tf)
/* Loop over interior faces in the thread, filling p_array
with face pressure and x_array with centroid */
{
p_array[f] = F_P(f, tf);
F_CENTROID(x_array[f], f, tf);
}
end_f_loop(f, tf)
/* Send data from node 1,2, ... to node 0 */
Message0("nstartn");
if(! I_AM_NODE_ZERO_P) /* Only SEND data from nodes 1,2... */
{
PRF_CSEND_REAL(node_zero, p_array, n_faces, myid);
PRF_CSEND_REAL(node_zero, x_array[0], ND_ND*n_faces, myid);
}
else
{/* Node-0 has its own data,
so list it out first */
Message0("nnList of Pressures...n");
for(j=0; j /* n_faces is currently node-0 value */
{
# if RP_3D
Message0("%12.4e %12.4e %12.4e %12.4en",
x_array[j][0], x_array[j][1], x_array[j][2], p_array[j]);
# else /* 2D */
Message0("%12.4e %12.4e %12.4en",
x_array[j][0], x_array[j][1], p_array[j]);
# endif
}
}
/* Node-0 must now RECV data from the other nodes and list that too */
if(I_AM_NODE_ZERO_P)
{
compute_node_loop_not_zero(i)
/* See para.h for definition of this loop */
{
PRF_CRECV_INT(i, &n_faces, 1, i);
/* n_faces now value for node-i */
/* Reallocate memory for arrays for node-i */
p_array=(real *)realloc(p_array, n_faces*sizeof(real));
x_array=(real(*)[ND_ND])realloc(x_array,ND_ND*n_faces*sizeof(real));
/* Receive data */
PRF_CRECV_REAL(i, p_array, n_faces, i);
PRF_CRECV_REAL(i, x_array[0], ND_ND*n_faces, i);
for(j=0; j {
# if RP_3D
Message0("%12.4e %12.4e %12.4e %12.4en",x_array[j][0], x_array[j][1], x_array[j][2], p_array[j]);
# else /* 2D */
Message0("%12.4e %12.4e %12.4en",x_array[j][0], x_array[j][1], p_array[j]);
# endif
}
}
}
free(p_array); /* Each array has to be freed before function exit */
free(x_array);
#endif /* ! RP_HOST */
}
4 计算节点间数据交换宏
EXCHANGE_SVAR_MESSAGE、EXCHANGE_SVAR_MESSAGE_EXT和EXCHANGE_SVAR_FACE_MESSAGE可用于在计算节点之间交换存储变量(SV_…)。EXCHANGE_SVAR_MESSAGE和EXCHANGE_SVAR_MESSAGE_EXT在计算节点之间交换cell数据,而EXCHANGE_SVAR_FACE_MESSAGE在计算节点之间交换face数据。EXCHANGE_SVAR_MESSAGE用于在常规外部单元上交换数据,EXCHANGE_SVAR_MESSAGE_EXT用于在常规和扩展外部单元上交换数据。
宏形式:
EXCHANGE_SVAR_FACE_MESSAGE(domain, (SV_P, SV_NULL));
EXCHANGE_SVAR_MESSAGE(domain, (SV_P, SV_NULL));
EXCHANGE_SVAR_MESSAGE_EXT(domain, (SV_P, SV_NULL));
EXCHANGE_SVAR_FACE_MESSAGE()在udf中很少用户。用户可以在计算节点之间交换多个存储变量。存储变量名由参数列表中的逗号分隔,列表以SV_NULL结束。例如,EXCHANGE_SVAR_MESSAGE(domain, (SV_P, SV_T, SV_NULL))用于交换单元压力和温度变量。用户可以从包含变量定义语句的头文件中确定存储变量名。例如,假设想要与相邻的计算节点交换cell pressure (C_P),可以查看包含C_P (mc .h)定义的头文件,并确定cell pressure的存储变量为SV_P,此时需要将存储变量传递给exchange宏。
并行计算的消息传递及其重要,设计不好的话会极大地影响到并行效率。在并行代码编写的过程中,一定要小心再小心。
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册